Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Null and Alternative Hypotheses | Definitions & Examples

Null & Alternative Hypotheses | Definitions, Templates & Examples
Published on May 6, 2022 by Shaun Turney . Revised on June 22, 2023.
The null and alternative hypotheses are two competing claims that researchers weigh evidence for and against using a statistical test :
- Null hypothesis ( H 0 ): There’s no effect in the population .
- Alternative hypothesis ( H a or H 1 ) : There’s an effect in the population.
Table of contents
Answering your research question with hypotheses, what is a null hypothesis, what is an alternative hypothesis, similarities and differences between null and alternative hypotheses, how to write null and alternative hypotheses, other interesting articles, frequently asked questions.
The null and alternative hypotheses offer competing answers to your research question . When the research question asks “Does the independent variable affect the dependent variable?”:
- The null hypothesis ( H 0 ) answers “No, there’s no effect in the population.”
- The alternative hypothesis ( H a ) answers “Yes, there is an effect in the population.”
The null and alternative are always claims about the population. That’s because the goal of hypothesis testing is to make inferences about a population based on a sample . Often, we infer whether there’s an effect in the population by looking at differences between groups or relationships between variables in the sample. It’s critical for your research to write strong hypotheses .
You can use a statistical test to decide whether the evidence favors the null or alternative hypothesis. Each type of statistical test comes with a specific way of phrasing the null and alternative hypothesis. However, the hypotheses can also be phrased in a general way that applies to any test.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

The null hypothesis is the claim that there’s no effect in the population.
If the sample provides enough evidence against the claim that there’s no effect in the population ( p ≤ α), then we can reject the null hypothesis . Otherwise, we fail to reject the null hypothesis.
Although “fail to reject” may sound awkward, it’s the only wording that statisticians accept . Be careful not to say you “prove” or “accept” the null hypothesis.
Null hypotheses often include phrases such as “no effect,” “no difference,” or “no relationship.” When written in mathematical terms, they always include an equality (usually =, but sometimes ≥ or ≤).
You can never know with complete certainty whether there is an effect in the population. Some percentage of the time, your inference about the population will be incorrect. When you incorrectly reject the null hypothesis, it’s called a type I error . When you incorrectly fail to reject it, it’s a type II error.
Examples of null hypotheses
The table below gives examples of research questions and null hypotheses. There’s always more than one way to answer a research question, but these null hypotheses can help you get started.
*Note that some researchers prefer to always write the null hypothesis in terms of “no effect” and “=”. It would be fine to say that daily meditation has no effect on the incidence of depression and p 1 = p 2 .
The alternative hypothesis ( H a ) is the other answer to your research question . It claims that there’s an effect in the population.
Often, your alternative hypothesis is the same as your research hypothesis. In other words, it’s the claim that you expect or hope will be true.
The alternative hypothesis is the complement to the null hypothesis. Null and alternative hypotheses are exhaustive, meaning that together they cover every possible outcome. They are also mutually exclusive, meaning that only one can be true at a time.
Alternative hypotheses often include phrases such as “an effect,” “a difference,” or “a relationship.” When alternative hypotheses are written in mathematical terms, they always include an inequality (usually ≠, but sometimes < or >). As with null hypotheses, there are many acceptable ways to phrase an alternative hypothesis.
Examples of alternative hypotheses
The table below gives examples of research questions and alternative hypotheses to help you get started with formulating your own.
Null and alternative hypotheses are similar in some ways:
- They’re both answers to the research question.
- They both make claims about the population.
- They’re both evaluated by statistical tests.
However, there are important differences between the two types of hypotheses, summarized in the following table.
Prevent plagiarism. Run a free check.
To help you write your hypotheses, you can use the template sentences below. If you know which statistical test you’re going to use, you can use the test-specific template sentences. Otherwise, you can use the general template sentences.
General template sentences
The only thing you need to know to use these general template sentences are your dependent and independent variables. To write your research question, null hypothesis, and alternative hypothesis, fill in the following sentences with your variables:
Does independent variable affect dependent variable ?
- Null hypothesis ( H 0 ): Independent variable does not affect dependent variable.
- Alternative hypothesis ( H a ): Independent variable affects dependent variable.
Test-specific template sentences
Once you know the statistical test you’ll be using, you can write your hypotheses in a more precise and mathematical way specific to the test you chose. The table below provides template sentences for common statistical tests.
Note: The template sentences above assume that you’re performing one-tailed tests . One-tailed tests are appropriate for most studies.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
The null hypothesis is often abbreviated as H 0 . When the null hypothesis is written using mathematical symbols, it always includes an equality symbol (usually =, but sometimes ≥ or ≤).
The alternative hypothesis is often abbreviated as H a or H 1 . When the alternative hypothesis is written using mathematical symbols, it always includes an inequality symbol (usually ≠, but sometimes < or >).
A research hypothesis is your proposed answer to your research question. The research hypothesis usually includes an explanation (“ x affects y because …”).
A statistical hypothesis, on the other hand, is a mathematical statement about a population parameter. Statistical hypotheses always come in pairs: the null and alternative hypotheses . In a well-designed study , the statistical hypotheses correspond logically to the research hypothesis.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Turney, S. (2023, June 22). Null & Alternative Hypotheses | Definitions, Templates & Examples. Scribbr. Retrieved March 25, 2024, from https://www.scribbr.com/statistics/null-and-alternative-hypotheses/
Is this article helpful?

Shaun Turney
Other students also liked, inferential statistics | an easy introduction & examples, hypothesis testing | a step-by-step guide with easy examples, type i & type ii errors | differences, examples, visualizations, what is your plagiarism score.
Research Hypothesis In Psychology: Types, & Examples
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
A research hypothesis, in its plural form “hypotheses,” is a specific, testable prediction about the anticipated results of a study, established at its outset. It is a key component of the scientific method .
Hypotheses connect theory to data and guide the research process towards expanding scientific understanding
Some key points about hypotheses:
- A hypothesis expresses an expected pattern or relationship. It connects the variables under investigation.
- It is stated in clear, precise terms before any data collection or analysis occurs. This makes the hypothesis testable.
- A hypothesis must be falsifiable. It should be possible, even if unlikely in practice, to collect data that disconfirms rather than supports the hypothesis.
- Hypotheses guide research. Scientists design studies to explicitly evaluate hypotheses about how nature works.
- For a hypothesis to be valid, it must be testable against empirical evidence. The evidence can then confirm or disprove the testable predictions.
- Hypotheses are informed by background knowledge and observation, but go beyond what is already known to propose an explanation of how or why something occurs.
Predictions typically arise from a thorough knowledge of the research literature, curiosity about real-world problems or implications, and integrating this to advance theory. They build on existing literature while providing new insight.
Types of Research Hypotheses
Alternative hypothesis.
The research hypothesis is often called the alternative or experimental hypothesis in experimental research.
It typically suggests a potential relationship between two key variables: the independent variable, which the researcher manipulates, and the dependent variable, which is measured based on those changes.
The alternative hypothesis states a relationship exists between the two variables being studied (one variable affects the other).
A hypothesis is a testable statement or prediction about the relationship between two or more variables. It is a key component of the scientific method. Some key points about hypotheses:
- Important hypotheses lead to predictions that can be tested empirically. The evidence can then confirm or disprove the testable predictions.
In summary, a hypothesis is a precise, testable statement of what researchers expect to happen in a study and why. Hypotheses connect theory to data and guide the research process towards expanding scientific understanding.
An experimental hypothesis predicts what change(s) will occur in the dependent variable when the independent variable is manipulated.
It states that the results are not due to chance and are significant in supporting the theory being investigated.
The alternative hypothesis can be directional, indicating a specific direction of the effect, or non-directional, suggesting a difference without specifying its nature. It’s what researchers aim to support or demonstrate through their study.
Null Hypothesis
The null hypothesis states no relationship exists between the two variables being studied (one variable does not affect the other). There will be no changes in the dependent variable due to manipulating the independent variable.
It states results are due to chance and are not significant in supporting the idea being investigated.
The null hypothesis, positing no effect or relationship, is a foundational contrast to the research hypothesis in scientific inquiry. It establishes a baseline for statistical testing, promoting objectivity by initiating research from a neutral stance.
Many statistical methods are tailored to test the null hypothesis, determining the likelihood of observed results if no true effect exists.
This dual-hypothesis approach provides clarity, ensuring that research intentions are explicit, and fosters consistency across scientific studies, enhancing the standardization and interpretability of research outcomes.
Nondirectional Hypothesis
A non-directional hypothesis, also known as a two-tailed hypothesis, predicts that there is a difference or relationship between two variables but does not specify the direction of this relationship.
It merely indicates that a change or effect will occur without predicting which group will have higher or lower values.
For example, “There is a difference in performance between Group A and Group B” is a non-directional hypothesis.
Directional Hypothesis
A directional (one-tailed) hypothesis predicts the nature of the effect of the independent variable on the dependent variable. It predicts in which direction the change will take place. (i.e., greater, smaller, less, more)
It specifies whether one variable is greater, lesser, or different from another, rather than just indicating that there’s a difference without specifying its nature.
For example, “Exercise increases weight loss” is a directional hypothesis.

Falsifiability
The Falsification Principle, proposed by Karl Popper , is a way of demarcating science from non-science. It suggests that for a theory or hypothesis to be considered scientific, it must be testable and irrefutable.
Falsifiability emphasizes that scientific claims shouldn’t just be confirmable but should also have the potential to be proven wrong.
It means that there should exist some potential evidence or experiment that could prove the proposition false.
However many confirming instances exist for a theory, it only takes one counter observation to falsify it. For example, the hypothesis that “all swans are white,” can be falsified by observing a black swan.
For Popper, science should attempt to disprove a theory rather than attempt to continually provide evidence to support a research hypothesis.
Can a Hypothesis be Proven?
Hypotheses make probabilistic predictions. They state the expected outcome if a particular relationship exists. However, a study result supporting a hypothesis does not definitively prove it is true.
All studies have limitations. There may be unknown confounding factors or issues that limit the certainty of conclusions. Additional studies may yield different results.
In science, hypotheses can realistically only be supported with some degree of confidence, not proven. The process of science is to incrementally accumulate evidence for and against hypothesized relationships in an ongoing pursuit of better models and explanations that best fit the empirical data. But hypotheses remain open to revision and rejection if that is where the evidence leads.
- Disproving a hypothesis is definitive. Solid disconfirmatory evidence will falsify a hypothesis and require altering or discarding it based on the evidence.
- However, confirming evidence is always open to revision. Other explanations may account for the same results, and additional or contradictory evidence may emerge over time.
We can never 100% prove the alternative hypothesis. Instead, we see if we can disprove, or reject the null hypothesis.
If we reject the null hypothesis, this doesn’t mean that our alternative hypothesis is correct but does support the alternative/experimental hypothesis.
Upon analysis of the results, an alternative hypothesis can be rejected or supported, but it can never be proven to be correct. We must avoid any reference to results proving a theory as this implies 100% certainty, and there is always a chance that evidence may exist which could refute a theory.
How to Write a Hypothesis
- Identify variables . The researcher manipulates the independent variable and the dependent variable is the measured outcome.
- Operationalized the variables being investigated . Operationalization of a hypothesis refers to the process of making the variables physically measurable or testable, e.g. if you are about to study aggression, you might count the number of punches given by participants.
- Decide on a direction for your prediction . If there is evidence in the literature to support a specific effect of the independent variable on the dependent variable, write a directional (one-tailed) hypothesis. If there are limited or ambiguous findings in the literature regarding the effect of the independent variable on the dependent variable, write a non-directional (two-tailed) hypothesis.
- Make it Testable : Ensure your hypothesis can be tested through experimentation or observation. It should be possible to prove it false (principle of falsifiability).
- Clear & concise language . A strong hypothesis is concise (typically one to two sentences long), and formulated using clear and straightforward language, ensuring it’s easily understood and testable.
Consider a hypothesis many teachers might subscribe to: students work better on Monday morning than on Friday afternoon (IV=Day, DV= Standard of work).
Now, if we decide to study this by giving the same group of students a lesson on a Monday morning and a Friday afternoon and then measuring their immediate recall of the material covered in each session, we would end up with the following:
- The alternative hypothesis states that students will recall significantly more information on a Monday morning than on a Friday afternoon.
- The null hypothesis states that there will be no significant difference in the amount recalled on a Monday morning compared to a Friday afternoon. Any difference will be due to chance or confounding factors.
More Examples
- Memory : Participants exposed to classical music during study sessions will recall more items from a list than those who studied in silence.
- Social Psychology : Individuals who frequently engage in social media use will report higher levels of perceived social isolation compared to those who use it infrequently.
- Developmental Psychology : Children who engage in regular imaginative play have better problem-solving skills than those who don’t.
- Clinical Psychology : Cognitive-behavioral therapy will be more effective in reducing symptoms of anxiety over a 6-month period compared to traditional talk therapy.
- Cognitive Psychology : Individuals who multitask between various electronic devices will have shorter attention spans on focused tasks than those who single-task.
- Health Psychology : Patients who practice mindfulness meditation will experience lower levels of chronic pain compared to those who don’t meditate.
- Organizational Psychology : Employees in open-plan offices will report higher levels of stress than those in private offices.
- Behavioral Psychology : Rats rewarded with food after pressing a lever will press it more frequently than rats who receive no reward.

- Privacy Policy
Buy Me a Coffee
Home » What is a Hypothesis – Types, Examples and Writing Guide
What is a Hypothesis – Types, Examples and Writing Guide
Table of Contents

Definition:
Hypothesis is an educated guess or proposed explanation for a phenomenon, based on some initial observations or data. It is a tentative statement that can be tested and potentially proven or disproven through further investigation and experimentation.
Hypothesis is often used in scientific research to guide the design of experiments and the collection and analysis of data. It is an essential element of the scientific method, as it allows researchers to make predictions about the outcome of their experiments and to test those predictions to determine their accuracy.
Types of Hypothesis
Types of Hypothesis are as follows:
Research Hypothesis
A research hypothesis is a statement that predicts a relationship between variables. It is usually formulated as a specific statement that can be tested through research, and it is often used in scientific research to guide the design of experiments.
Null Hypothesis
The null hypothesis is a statement that assumes there is no significant difference or relationship between variables. It is often used as a starting point for testing the research hypothesis, and if the results of the study reject the null hypothesis, it suggests that there is a significant difference or relationship between variables.
Alternative Hypothesis
An alternative hypothesis is a statement that assumes there is a significant difference or relationship between variables. It is often used as an alternative to the null hypothesis and is tested against the null hypothesis to determine which statement is more accurate.
Directional Hypothesis
A directional hypothesis is a statement that predicts the direction of the relationship between variables. For example, a researcher might predict that increasing the amount of exercise will result in a decrease in body weight.
Non-directional Hypothesis
A non-directional hypothesis is a statement that predicts the relationship between variables but does not specify the direction. For example, a researcher might predict that there is a relationship between the amount of exercise and body weight, but they do not specify whether increasing or decreasing exercise will affect body weight.
Statistical Hypothesis
A statistical hypothesis is a statement that assumes a particular statistical model or distribution for the data. It is often used in statistical analysis to test the significance of a particular result.
Composite Hypothesis
A composite hypothesis is a statement that assumes more than one condition or outcome. It can be divided into several sub-hypotheses, each of which represents a different possible outcome.
Empirical Hypothesis
An empirical hypothesis is a statement that is based on observed phenomena or data. It is often used in scientific research to develop theories or models that explain the observed phenomena.
Simple Hypothesis
A simple hypothesis is a statement that assumes only one outcome or condition. It is often used in scientific research to test a single variable or factor.
Complex Hypothesis
A complex hypothesis is a statement that assumes multiple outcomes or conditions. It is often used in scientific research to test the effects of multiple variables or factors on a particular outcome.
Applications of Hypothesis
Hypotheses are used in various fields to guide research and make predictions about the outcomes of experiments or observations. Here are some examples of how hypotheses are applied in different fields:
- Science : In scientific research, hypotheses are used to test the validity of theories and models that explain natural phenomena. For example, a hypothesis might be formulated to test the effects of a particular variable on a natural system, such as the effects of climate change on an ecosystem.
- Medicine : In medical research, hypotheses are used to test the effectiveness of treatments and therapies for specific conditions. For example, a hypothesis might be formulated to test the effects of a new drug on a particular disease.
- Psychology : In psychology, hypotheses are used to test theories and models of human behavior and cognition. For example, a hypothesis might be formulated to test the effects of a particular stimulus on the brain or behavior.
- Sociology : In sociology, hypotheses are used to test theories and models of social phenomena, such as the effects of social structures or institutions on human behavior. For example, a hypothesis might be formulated to test the effects of income inequality on crime rates.
- Business : In business research, hypotheses are used to test the validity of theories and models that explain business phenomena, such as consumer behavior or market trends. For example, a hypothesis might be formulated to test the effects of a new marketing campaign on consumer buying behavior.
- Engineering : In engineering, hypotheses are used to test the effectiveness of new technologies or designs. For example, a hypothesis might be formulated to test the efficiency of a new solar panel design.
How to write a Hypothesis
Here are the steps to follow when writing a hypothesis:
Identify the Research Question
The first step is to identify the research question that you want to answer through your study. This question should be clear, specific, and focused. It should be something that can be investigated empirically and that has some relevance or significance in the field.
Conduct a Literature Review
Before writing your hypothesis, it’s essential to conduct a thorough literature review to understand what is already known about the topic. This will help you to identify the research gap and formulate a hypothesis that builds on existing knowledge.
Determine the Variables
The next step is to identify the variables involved in the research question. A variable is any characteristic or factor that can vary or change. There are two types of variables: independent and dependent. The independent variable is the one that is manipulated or changed by the researcher, while the dependent variable is the one that is measured or observed as a result of the independent variable.
Formulate the Hypothesis
Based on the research question and the variables involved, you can now formulate your hypothesis. A hypothesis should be a clear and concise statement that predicts the relationship between the variables. It should be testable through empirical research and based on existing theory or evidence.
Write the Null Hypothesis
The null hypothesis is the opposite of the alternative hypothesis, which is the hypothesis that you are testing. The null hypothesis states that there is no significant difference or relationship between the variables. It is important to write the null hypothesis because it allows you to compare your results with what would be expected by chance.
Refine the Hypothesis
After formulating the hypothesis, it’s important to refine it and make it more precise. This may involve clarifying the variables, specifying the direction of the relationship, or making the hypothesis more testable.
Examples of Hypothesis
Here are a few examples of hypotheses in different fields:
- Psychology : “Increased exposure to violent video games leads to increased aggressive behavior in adolescents.”
- Biology : “Higher levels of carbon dioxide in the atmosphere will lead to increased plant growth.”
- Sociology : “Individuals who grow up in households with higher socioeconomic status will have higher levels of education and income as adults.”
- Education : “Implementing a new teaching method will result in higher student achievement scores.”
- Marketing : “Customers who receive a personalized email will be more likely to make a purchase than those who receive a generic email.”
- Physics : “An increase in temperature will cause an increase in the volume of a gas, assuming all other variables remain constant.”
- Medicine : “Consuming a diet high in saturated fats will increase the risk of developing heart disease.”
Purpose of Hypothesis
The purpose of a hypothesis is to provide a testable explanation for an observed phenomenon or a prediction of a future outcome based on existing knowledge or theories. A hypothesis is an essential part of the scientific method and helps to guide the research process by providing a clear focus for investigation. It enables scientists to design experiments or studies to gather evidence and data that can support or refute the proposed explanation or prediction.
The formulation of a hypothesis is based on existing knowledge, observations, and theories, and it should be specific, testable, and falsifiable. A specific hypothesis helps to define the research question, which is important in the research process as it guides the selection of an appropriate research design and methodology. Testability of the hypothesis means that it can be proven or disproven through empirical data collection and analysis. Falsifiability means that the hypothesis should be formulated in such a way that it can be proven wrong if it is incorrect.
In addition to guiding the research process, the testing of hypotheses can lead to new discoveries and advancements in scientific knowledge. When a hypothesis is supported by the data, it can be used to develop new theories or models to explain the observed phenomenon. When a hypothesis is not supported by the data, it can help to refine existing theories or prompt the development of new hypotheses to explain the phenomenon.
When to use Hypothesis
Here are some common situations in which hypotheses are used:
- In scientific research , hypotheses are used to guide the design of experiments and to help researchers make predictions about the outcomes of those experiments.
- In social science research , hypotheses are used to test theories about human behavior, social relationships, and other phenomena.
- I n business , hypotheses can be used to guide decisions about marketing, product development, and other areas. For example, a hypothesis might be that a new product will sell well in a particular market, and this hypothesis can be tested through market research.
Characteristics of Hypothesis
Here are some common characteristics of a hypothesis:
- Testable : A hypothesis must be able to be tested through observation or experimentation. This means that it must be possible to collect data that will either support or refute the hypothesis.
- Falsifiable : A hypothesis must be able to be proven false if it is not supported by the data. If a hypothesis cannot be falsified, then it is not a scientific hypothesis.
- Clear and concise : A hypothesis should be stated in a clear and concise manner so that it can be easily understood and tested.
- Based on existing knowledge : A hypothesis should be based on existing knowledge and research in the field. It should not be based on personal beliefs or opinions.
- Specific : A hypothesis should be specific in terms of the variables being tested and the predicted outcome. This will help to ensure that the research is focused and well-designed.
- Tentative: A hypothesis is a tentative statement or assumption that requires further testing and evidence to be confirmed or refuted. It is not a final conclusion or assertion.
- Relevant : A hypothesis should be relevant to the research question or problem being studied. It should address a gap in knowledge or provide a new perspective on the issue.
Advantages of Hypothesis
Hypotheses have several advantages in scientific research and experimentation:
- Guides research: A hypothesis provides a clear and specific direction for research. It helps to focus the research question, select appropriate methods and variables, and interpret the results.
- Predictive powe r: A hypothesis makes predictions about the outcome of research, which can be tested through experimentation. This allows researchers to evaluate the validity of the hypothesis and make new discoveries.
- Facilitates communication: A hypothesis provides a common language and framework for scientists to communicate with one another about their research. This helps to facilitate the exchange of ideas and promotes collaboration.
- Efficient use of resources: A hypothesis helps researchers to use their time, resources, and funding efficiently by directing them towards specific research questions and methods that are most likely to yield results.
- Provides a basis for further research: A hypothesis that is supported by data provides a basis for further research and exploration. It can lead to new hypotheses, theories, and discoveries.
- Increases objectivity: A hypothesis can help to increase objectivity in research by providing a clear and specific framework for testing and interpreting results. This can reduce bias and increase the reliability of research findings.
Limitations of Hypothesis
Some Limitations of the Hypothesis are as follows:
- Limited to observable phenomena: Hypotheses are limited to observable phenomena and cannot account for unobservable or intangible factors. This means that some research questions may not be amenable to hypothesis testing.
- May be inaccurate or incomplete: Hypotheses are based on existing knowledge and research, which may be incomplete or inaccurate. This can lead to flawed hypotheses and erroneous conclusions.
- May be biased: Hypotheses may be biased by the researcher’s own beliefs, values, or assumptions. This can lead to selective interpretation of data and a lack of objectivity in research.
- Cannot prove causation: A hypothesis can only show a correlation between variables, but it cannot prove causation. This requires further experimentation and analysis.
- Limited to specific contexts: Hypotheses are limited to specific contexts and may not be generalizable to other situations or populations. This means that results may not be applicable in other contexts or may require further testing.
- May be affected by chance : Hypotheses may be affected by chance or random variation, which can obscure or distort the true relationship between variables.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples

Institutional Review Board – Application Sample...

Evaluating Research – Process, Examples and...
Module 9: Hypothesis Testing With One Sample
Null and alternative hypotheses, learning outcomes.
- Describe hypothesis testing in general and in practice
The actual test begins by considering two hypotheses . They are called the null hypothesis and the alternative hypothesis . These hypotheses contain opposing viewpoints.
H 0 : The null hypothesis: It is a statement about the population that either is believed to be true or is used to put forth an argument unless it can be shown to be incorrect beyond a reasonable doubt.
H a : The alternative hypothesis : It is a claim about the population that is contradictory to H 0 and what we conclude when we reject H 0 .
Since the null and alternative hypotheses are contradictory, you must examine evidence to decide if you have enough evidence to reject the null hypothesis or not. The evidence is in the form of sample data.
After you have determined which hypothesis the sample supports, you make adecision. There are two options for a decision . They are “reject H 0 ” if the sample information favors the alternative hypothesis or “do not reject H 0 ” or “decline to reject H 0 ” if the sample information is insufficient to reject the null hypothesis.
Mathematical Symbols Used in H 0 and H a :
H 0 always has a symbol with an equal in it. H a never has a symbol with an equal in it. The choice of symbol depends on the wording of the hypothesis test. However, be aware that many researchers (including one of the co-authors in research work) use = in the null hypothesis, even with > or < as the symbol in the alternative hypothesis. This practice is acceptable because we only make the decision to reject or not reject the null hypothesis.
H 0 : No more than 30% of the registered voters in Santa Clara County voted in the primary election. p ≤ 30
H a : More than 30% of the registered voters in Santa Clara County voted in the primary election. p > 30
A medical trial is conducted to test whether or not a new medicine reduces cholesterol by 25%. State the null and alternative hypotheses.
H 0 : The drug reduces cholesterol by 25%. p = 0.25
H a : The drug does not reduce cholesterol by 25%. p ≠ 0.25
We want to test whether the mean GPA of students in American colleges is different from 2.0 (out of 4.0). The null and alternative hypotheses are:
H 0 : μ = 2.0
H a : μ ≠ 2.0
We want to test whether the mean height of eighth graders is 66 inches. State the null and alternative hypotheses. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses. H 0 : μ __ 66 H a : μ __ 66
- H 0 : μ = 66
- H a : μ ≠ 66
We want to test if college students take less than five years to graduate from college, on the average. The null and alternative hypotheses are:
H 0 : μ ≥ 5
H a : μ < 5
We want to test if it takes fewer than 45 minutes to teach a lesson plan. State the null and alternative hypotheses. Fill in the correct symbol ( =, ≠, ≥, <, ≤, >) for the null and alternative hypotheses. H 0 : μ __ 45 H a : μ __ 45
- H 0 : μ ≥ 45
- H a : μ < 45
In an issue of U.S. News and World Report , an article on school standards stated that about half of all students in France, Germany, and Israel take advanced placement exams and a third pass. The same article stated that 6.6% of U.S. students take advanced placement exams and 4.4% pass. Test if the percentage of U.S. students who take advanced placement exams is more than 6.6%. State the null and alternative hypotheses.
H 0 : p ≤ 0.066
H a : p > 0.066
On a state driver’s test, about 40% pass the test on the first try. We want to test if more than 40% pass on the first try. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses. H 0 : p __ 0.40 H a : p __ 0.40
- H 0 : p = 0.40
- H a : p > 0.40
Concept Review
In a hypothesis test , sample data is evaluated in order to arrive at a decision about some type of claim. If certain conditions about the sample are satisfied, then the claim can be evaluated for a population. In a hypothesis test, we: Evaluate the null hypothesis , typically denoted with H 0 . The null is not rejected unless the hypothesis test shows otherwise. The null statement must always contain some form of equality (=, ≤ or ≥) Always write the alternative hypothesis , typically denoted with H a or H 1 , using less than, greater than, or not equals symbols, i.e., (≠, >, or <). If we reject the null hypothesis, then we can assume there is enough evidence to support the alternative hypothesis. Never state that a claim is proven true or false. Keep in mind the underlying fact that hypothesis testing is based on probability laws; therefore, we can talk only in terms of non-absolute certainties.
Formula Review
H 0 and H a are contradictory.
- OpenStax, Statistics, Null and Alternative Hypotheses. Provided by : OpenStax. Located at : http://cnx.org/contents/[email protected]:58/Introductory_Statistics . License : CC BY: Attribution
- Introductory Statistics . Authored by : Barbara Illowski, Susan Dean. Provided by : Open Stax. Located at : http://cnx.org/contents/[email protected] . License : CC BY: Attribution . License Terms : Download for free at http://cnx.org/contents/[email protected]
- Simple hypothesis testing | Probability and Statistics | Khan Academy. Authored by : Khan Academy. Located at : https://youtu.be/5D1gV37bKXY . License : All Rights Reserved . License Terms : Standard YouTube License

User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
6a.2 - steps for hypothesis tests, the logic of hypothesis testing section .
A hypothesis, in statistics, is a statement about a population parameter, where this statement typically is represented by some specific numerical value. In testing a hypothesis, we use a method where we gather data in an effort to gather evidence about the hypothesis.
How do we decide whether to reject the null hypothesis?
- If the sample data are consistent with the null hypothesis, then we do not reject it.
- If the sample data are inconsistent with the null hypothesis, but consistent with the alternative, then we reject the null hypothesis and conclude that the alternative hypothesis is true.
Six Steps for Hypothesis Tests Section
In hypothesis testing, there are certain steps one must follow. Below these are summarized into six such steps to conducting a test of a hypothesis.
- Set up the hypotheses and check conditions : Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as \(H_0 \), which is a statement of a particular parameter value. This hypothesis is assumed to be true until there is evidence to suggest otherwise. The second hypothesis is called the alternative, or research hypothesis, notated as \(H_a \). The alternative hypothesis is a statement of a range of alternative values in which the parameter may fall. One must also check that any conditions (assumptions) needed to run the test have been satisfied e.g. normality of data, independence, and number of success and failure outcomes.
- Decide on the significance level, \(\alpha \): This value is used as a probability cutoff for making decisions about the null hypothesis. This alpha value represents the probability we are willing to place on our test for making an incorrect decision in regards to rejecting the null hypothesis. The most common \(\alpha \) value is 0.05 or 5%. Other popular choices are 0.01 (1%) and 0.1 (10%).
- Calculate the test statistic: Gather sample data and calculate a test statistic where the sample statistic is compared to the parameter value. The test statistic is calculated under the assumption the null hypothesis is true and incorporates a measure of standard error and assumptions (conditions) related to the sampling distribution.
- Calculate probability value (p-value), or find the rejection region: A p-value is found by using the test statistic to calculate the probability of the sample data producing such a test statistic or one more extreme. The rejection region is found by using alpha to find a critical value; the rejection region is the area that is more extreme than the critical value. We discuss the p-value and rejection region in more detail in the next section.
- Make a decision about the null hypothesis: In this step, we decide to either reject the null hypothesis or decide to fail to reject the null hypothesis. Notice we do not make a decision where we will accept the null hypothesis.
- State an overall conclusion : Once we have found the p-value or rejection region, and made a statistical decision about the null hypothesis (i.e. we will reject the null or fail to reject the null), we then want to summarize our results into an overall conclusion for our test.
We will follow these six steps for the remainder of this Lesson. In the future Lessons, the steps will be followed but may not be explained explicitly.
Step 1 is a very important step to set up correctly. If your hypotheses are incorrect, your conclusion will be incorrect. In this next section, we practice with Step 1 for the one sample situations.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
1.2: The 7-Step Process of Statistical Hypothesis Testing
- Last updated
- Save as PDF
- Page ID 33320

- Penn State's Department of Statistics
- The Pennsylvania State University
We will cover the seven steps one by one.
Step 1: State the Null Hypothesis
The null hypothesis can be thought of as the opposite of the "guess" the researchers made: in this example, the biologist thinks the plant height will be different for the fertilizers. So the null would be that there will be no difference among the groups of plants. Specifically, in more statistical language the null for an ANOVA is that the means are the same. We state the null hypothesis as: \[H_{0}: \ \mu_{1} = \mu_{2} = \ldots = \mu_{T}\] for \(T\) levels of an experimental treatment.
Why do we do this? Why not simply test the working hypothesis directly? The answer lies in the Popperian Principle of Falsification. Karl Popper (a philosopher) discovered that we can't conclusively confirm a hypothesis, but we can conclusively negate one. So we set up a null hypothesis which is effectively the opposite of the working hypothesis. The hope is that based on the strength of the data, we will be able to negate or reject the null hypothesis and accept an alternative hypothesis. In other words, we usually see the working hypothesis in \(H_{A}\).
Step 2: State the Alternative Hypothesis
\[H_{A}: \ \text{treatment level means not all equal}\]
The reason we state the alternative hypothesis this way is that if the null is rejected, there are many possibilities.
For example, \(\mu_{1} \neq \mu_{2} = \ldots = \mu_{T}\) is one possibility, as is \(\mu_{1} = \mu_{2} \neq \mu_{3} = \ldots = \mu_{T}\). Many people make the mistake of stating the alternative hypothesis as \(mu_{1} \neq mu_{2} \neq \ldots \neq \mu_{T}\), which says that every mean differs from every other mean. This is a possibility, but only one of many possibilities. To cover all alternative outcomes, we resort to a verbal statement of "not all equal" and then follow up with mean comparisons to find out where differences among means exist. In our example, this means that fertilizer 1 may result in plants that are really tall, but fertilizers 2, 3, and the plants with no fertilizers don't differ from one another. A simpler way of thinking about this is that at least one mean is different from all others.
Step 3: Set \(\alpha\)
If we look at what can happen in a hypothesis test, we can construct the following contingency table:
You should be familiar with type I and type II errors from your introductory course. It is important to note that we want to set \(\alpha\) before the experiment ( a priori ) because the Type I error is the more grievous error to make. The typical value of \(\alpha\) is 0.05, establishing a 95% confidence level. For this course, we will assume \(\alpha\) =0.05, unless stated otherwise.
Step 4: Collect Data
Remember the importance of recognizing whether data is collected through an experimental design or observational study.
Step 5: Calculate a test statistic
For categorical treatment level means, we use an \(F\) statistic, named after R.A. Fisher. We will explore the mechanics of computing the \(F\) statistic beginning in Chapter 2. The \(F\) value we get from the data is labeled \(F_{\text{calculated}}\).
Step 6: Construct Acceptance / Rejection regions
As with all other test statistics, a threshold (critical) value of \(F\) is established. This \(F\) value can be obtained from statistical tables or software and is referred to as \(F_{\text{critical}}\) or \(F_{\alpha}\). As a reminder, this critical value is the minimum value for the test statistic (in this case the F test) for us to be able to reject the null.
The \(F\) distribution, \(F_{\alpha}\), and the location of acceptance and rejection regions are shown in the graph below:
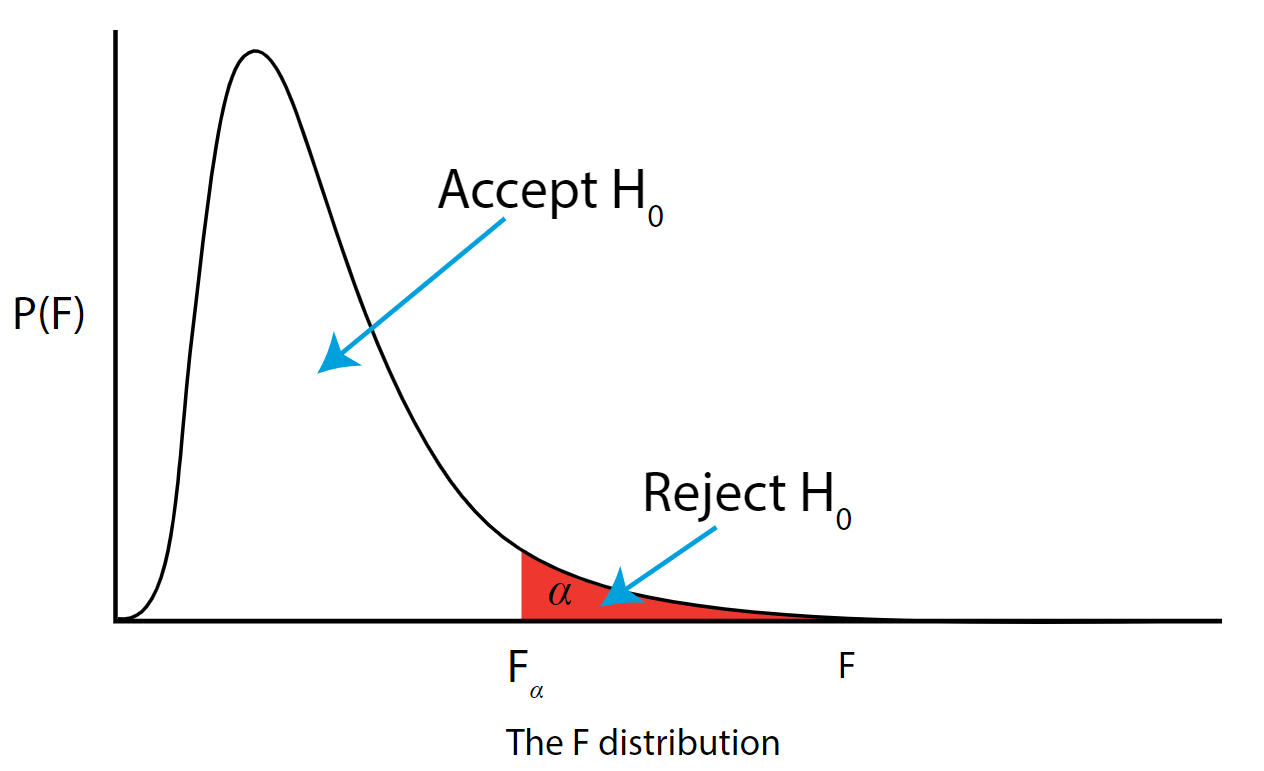.png?revision=1&size=bestfit&width=629&height=383 "hypothesis keywords")
Step 7: Based on steps 5 and 6, draw a conclusion about H0
If the \(F_{\text{\calculated}}\) from the data is larger than the \(F_{\alpha}\), then you are in the rejection region and you can reject the null hypothesis with \((1 - \alpha)\) level of confidence.
Note that modern statistical software condenses steps 6 and 7 by providing a \(p\)-value. The \(p\)-value here is the probability of getting an \(F_{\text{calculated}}\) even greater than what you observe assuming the null hypothesis is true. If by chance, the \(F_{\text{calculated}} = F_{\alpha}\), then the \(p\)-value would exactly equal \(\alpha\). With larger \(F_{\text{calculated}}\) values, we move further into the rejection region and the \(p\) - value becomes less than \(\alpha\). So the decision rule is as follows:
If the \(p\) - value obtained from the ANOVA is less than \(\alpha\), then reject \(H_{0}\) and accept \(H_{A}\).
If you are not familiar with this material, we suggest that you review course materials from your basic statistics course.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- R Soc Open Sci
- v.10(8); 2023 Aug
- PMC10465209
On the scope of scientific hypotheses
William hedley thompson.
1 Department of Applied Information Technology, University of Gothenburg, Gothenburg, Sweden
2 Institute of Neuroscience and Physiology, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden
3 Department of Pedagogical, Curricular and Professional Studies, Faculty of Education, University of Gothenburg, Gothenburg, Sweden
4 Department of Clinical Neuroscience, Karolinska Institutet, Stockholm, Sweden
Associated Data
This article has no additional data.
Hypotheses are frequently the starting point when undertaking the empirical portion of the scientific process. They state something that the scientific process will attempt to evaluate, corroborate, verify or falsify. Their purpose is to guide the types of data we collect, analyses we conduct, and inferences we would like to make. Over the last decade, metascience has advocated for hypotheses being in preregistrations or registered reports, but how to formulate these hypotheses has received less attention. Here, we argue that hypotheses can vary in specificity along at least three independent dimensions: the relationship, the variables, and the pipeline. Together, these dimensions form the scope of the hypothesis. We demonstrate how narrowing the scope of a hypothesis in any of these three ways reduces the hypothesis space and that this reduction is a type of novelty. Finally, we discuss how this formulation of hypotheses can guide researchers to formulate the appropriate scope for their hypotheses and should aim for neither too broad nor too narrow a scope. This framework can guide hypothesis-makers when formulating their hypotheses by helping clarify what is being tested, chaining results to previous known findings, and demarcating what is explicitly tested in the hypothesis.
1. Introduction
Hypotheses are an important part of the scientific process. However, surprisingly little attention is given to hypothesis-making compared to other skills in the scientist's skillset within current discussions aimed at improving scientific practice. Perhaps this lack of emphasis is because the formulation of the hypothesis is often considered less relevant, as it is ultimately the scientific process that will eventually decide the veracity of the hypothesis. However, there are more hypotheses than scientific studies as selection occurs at various stages: from funder selection and researcher's interests. So which hypotheses are worthwhile to pursue? Which hypotheses are the most effective or pragmatic for extending or enhancing our collective knowledge? We consider the answer to these questions by discussing how broad or narrow a hypothesis can or should be (i.e. its scope).
We begin by considering that the two statements below are both hypotheses and vary in scope:
- H 1 : For every 1 mg decrease of x , y will increase by, on average, 2.5 points.
- H 2 : Changes in x 1 or x 2 correlate with y levels in some way.
Clearly, the specificity of the two hypotheses is very different. H 1 states a precise relationship between two variables ( x and y ), while H 2 specifies a vaguer relationship and does not specify which variables will show the relationship. However, they are both still hypotheses about how x and y relate to each other. This claim of various degrees of the broadness of hypotheses is, in and of itself, not novel. In Epistemetrics, Rescher [ 1 ], while drawing upon the physicist Duhem's work, develops what he calls Duhem's Law. This law considers a trade-off between certainty or precision in statements about physics when evaluating them. Duhem's Law states that narrower hypotheses, such as H 1 above, are more precise but less likely to be evaluated as true than broader ones, such as H 2 above. Similarly, Popper, when discussing theories, describes the reverse relationship between content and probability of a theory being true, i.e. with increased content, there is a decrease in probability and vice versa [ 2 ]. Here we will argue that it is important that both H 1 and H 2 are still valid scientific hypotheses, and their appropriateness depends on certain scientific questions.
The question of hypothesis scope is relevant since there are multiple recent prescriptions to improve science, ranging from topics about preregistrations [ 3 ], registered reports [ 4 ], open science [ 5 ], standardization [ 6 ], generalizability [ 7 ], multiverse analyses [ 8 ], dataset reuse [ 9 ] and general questionable research practices [ 10 ]. Within each of these issues, there are arguments to demarcate between confirmatory and exploratory research or normative prescriptions about how science should be done (e.g. science is ‘bad’ or ‘worse’ if code/data are not open). Despite all these discussions and improvements, much can still be done to improve hypothesis-making. A recent evaluation of preregistered studies in psychology found that over half excluded the preregistered hypotheses [ 11 ]. Further, evaluations of hypotheses in ecology showed that most hypotheses are not explicitly stated [ 12 , 13 ]. Other research has shown that obfuscated hypotheses are more prevalent in retracted research [ 14 ]. There have been recommendations for simpler hypotheses in psychology to avoid misinterpretations and misspecifications [ 15 ]. Finally, several evaluations of preregistration practices have found that a significant proportion of articles do not abide by their stated hypothesis or add additional hypotheses [ 11 , 16 – 18 ]. In sum, while multiple efforts exist to improve scientific practice, our hypothesis-making could improve.
One of our intentions is to provide hypothesis-makers with tools to assist them when making hypotheses. We consider this useful and timely as, with preregistrations becoming more frequent, the hypothesis-making process is now open and explicit . However, preregistrations are difficult to write [ 19 ], and preregistered articles can change or omit hypotheses [ 11 ] or they are vague and certain degrees of freedom hard to control for [ 16 – 18 ]. One suggestion has been to do less confirmatory research [ 7 , 20 ]. While we agree that all research does not need to be confirmatory, we also believe that not all preregistrations of confirmatory work must test narrow hypotheses. We think there is a possible point of confusion that the specificity in preregistrations, where researcher degrees of freedom should be stated, necessitates the requirement that the hypothesis be narrow. Our belief that this confusion is occurring is supported by the study Akker et al . [ 11 ] where they found that 18% of published psychology studies changed their preregistered hypothesis (e.g. its direction), and 60% of studies selectively reported hypotheses in some way. It is along these lines that we feel the framework below can be useful to help formulate appropriate hypotheses to mitigate these identified issues.
We consider this article to be a discussion of the researcher's different choices when formulating hypotheses and to help link hypotheses over time. Here we aim to deconstruct what aspects there are in the hypothesis about their specificity. Throughout this article, we intend to be neutral to many different philosophies of science relating to the scientific method (i.e. how one determines the veracity of a hypothesis). Our idea of neutrality here is that whether a researcher adheres to falsification, verification, pragmatism, or some other philosophy of science, then this framework can be used when formulating hypotheses. 1
The framework this article advocates for is that there are (at least) three dimensions that hypotheses vary along regarding their narrowness and broadness: the selection of relationships, variables, and pipelines. We believe this discussion is fruitful for the current debate regarding normative practices as some positions make, sometimes implicit, commitments about which set of hypotheses the scientific community ought to consider good or permissible. We proceed by outlining a working definition of ‘scientific hypothesis' and then discuss how it relates to theory. Then, we justify how hypotheses can vary along the three dimensions. Using this framework, we then discuss the scopes in relation to appropriate hypothesis-making and an argument about what constitutes a scientifically novel hypothesis. We end the article with practical advice for researchers who wish to use this framework.
2. The scientific hypothesis
In this section, we will describe a functional and descriptive role regarding how scientists use hypotheses. Jeong & Kwon [ 21 ] investigated and summarized the different uses the concept of ‘hypothesis’ had in philosophical and scientific texts. They identified five meanings: assumption, tentative explanation, tentative cause, tentative law, and prediction. Jeong & Kwon [ 21 ] further found that researchers in science and philosophy used all the different definitions of hypotheses, although there was some variance in frequency between fields. Here we see, descriptively , that the way researchers use the word ‘hypothesis’ is diverse and has a wide range in specificity and function. However, whichever meaning a hypothesis has, it aims to be true, adequate, accurate or useful in some way.
Not all hypotheses are ‘scientific hypotheses'. For example, consider the detective trying to solve a crime and hypothesizing about the perpetrator. Such a hypothesis still aims to be true and is a tentative explanation but differs from the scientific hypothesis. The difference is that the researcher, unlike the detective, evaluates the hypothesis with the scientific method and submits the work for evaluation by the scientific community. Thus a scientific hypothesis entails a commitment to evaluate the statement with the scientific process . 2 Additionally, other types of hypotheses can exist. As discussed in more detail below, scientific theories generate not only scientific hypotheses but also contain auxiliary hypotheses. The latter refers to additional assumptions considered to be true and not explicitly evaluated. 3
Next, the scientific hypothesis is generally made antecedent to the evaluation. This does not necessitate that the event (e.g. in archaeology) or the data collection (e.g. with open data reuse) must be collected before the hypothesis is made, but that the evaluation of the hypothesis cannot happen before its formulation. This claim state does deny the utility of exploratory hypothesis testing of post hoc hypotheses (see [ 25 ]). However, previous results and exploration can generate new hypotheses (e.g. via abduction [ 22 , 26 – 28 ], which is the process of creating hypotheses from evidence), which is an important part of science [ 29 – 32 ], but crucially, while these hypotheses are important and can be the conclusion of exploratory work, they have yet to be evaluated (by whichever method of choice). Hence, they still conform to the antecedency requirement. A further way to justify the antecedency is seen in the practice of formulating a post hoc hypothesis, and considering it to have been evaluated is seen as a questionable research practice (known as ‘hypotheses after results are known’ or HARKing [ 33 ]). 4
While there is a varying range of specificity, is the hypothesis a critical part of all scientific work, or is it reserved for some subset of investigations? There are different opinions regarding this. Glass and Hall, for example, argue that the term only refers to falsifiable research, and model-based research uses verification [ 36 ]. However, this opinion does not appear to be the consensus. Osimo and Rumiati argue that any model based on or using data is never wholly free from hypotheses, as hypotheses can, even implicitly, infiltrate the data collection [ 37 ]. For our definition, we will consider hypotheses that can be involved in different forms of scientific evaluation (i.e. not just falsification), but we do not exclude the possibility of hypothesis-free scientific work.
Finally, there is a debate about whether theories or hypotheses should be linguistic or formal [ 38 – 40 ]. Neither side in this debate argues that verbal or formal hypotheses are not possible, but instead, they discuss normative practices. Thus, for our definition, both linguistic and formal hypotheses are considered viable.
Considering the above discussion, let us summarize the scientific process and the scientific hypothesis: a hypothesis guides what type of data are sampled and what analysis will be done. With the new observations, evidence is analysed or quantified in some way (often using inferential statistics) to judge the hypothesis's truth value, utility, credibility, or likelihood. The following working definition captures the above:
- Scientific hypothesis : an implicit or explicit statement that can be verbal or formal. The hypothesis makes a statement about some natural phenomena (via an assumption, explanation, cause, law or prediction). The scientific hypothesis is made antecedent to performing a scientific process where there is a commitment to evaluate it.
For simplicity, we will only use the term ‘hypothesis’ for ‘scientific hypothesis' to refer to the above definition for the rest of the article except when it is necessary to distinguish between other types of hypotheses. Finally, this definition could further be restrained in multiple ways (e.g. only explicit hypotheses are allowed, or assumptions are never hypotheses). However, if the definition is more (or less) restrictive, it has little implication for the argument below.
3. The hypothesis, theory and auxiliary assumptions
While we have a definition of the scientific hypothesis, we have yet to link it with how it relates to scientific theory, where there is frequently some interconnection (i.e. a hypothesis tests a scientific theory). Generally, for this paper, we believe our argument applies regardless of how scientific theory is defined. Further, some research lacks theory, sometimes called convenience or atheoretical studies [ 41 ]. Here a hypothesis can be made without a wider theory—and our framework fits here too. However, since many consider hypotheses to be defined or deducible from scientific theory, there is an important connection between the two. Therefore, we will briefly clarify how hypotheses relate to common formulations of scientific theory.
A scientific theory is generally a set of axioms or statements about some objects, properties and their relations relating to some phenomena. Hypotheses can often be deduced from the theory. Additionally, a theory has boundary conditions. The boundary conditions specify the domain of the theory stating under what conditions it applies (e.g. all things with a central neural system, humans, women, university teachers) [ 42 ]. Boundary conditions of a theory will consequently limit all hypotheses deduced from the theory. For example, with a boundary condition ‘applies to all humans’, then the subsequent hypotheses deduced from the theory are limited to being about humans. While this limitation of the hypothesis by the theory's boundary condition exists, all the considerations about a hypothesis scope detailed below still apply within the boundary conditions. Finally, it is also possible (depending on the definition of scientific theory) for a hypothesis to test the same theory under different boundary conditions. 5
The final consideration relating scientific theory to scientific hypotheses is auxiliary hypotheses. These hypotheses are theories or assumptions that are considered true simultaneously with the theory. Most philosophies of science from Popper's background knowledge [ 24 ], Kuhn's paradigms during normal science [ 44 ], and Laktos' protective belt [ 45 ] all have their own versions of this auxiliary or background information that is required for the hypothesis to test the theory. For example, Meelh [ 46 ] auxiliary theories/assumptions are needed to go from theoretical terms to empirical terms (e.g. neural activity can be inferred from blood oxygenation in fMRI research or reaction time to an indicator of cognition) and auxiliary theories about instruments (e.g. the experimental apparatus works as intended) and more (see also Other approaches to categorizing hypotheses below). As noted in the previous section, there is a difference between these auxiliary hypotheses, regardless of their definition, and the scientific hypothesis defined above. Recall that our definition of the scientific hypothesis included a commitment to evaluate it. There are no such commitments with auxiliary hypotheses, but rather they are assumed to be correct to test the theory adequately. This distinction proves to be important as auxiliary hypotheses are still part of testing a theory but are separate from the hypothesis to be evaluated (discussed in more detail below).
4. The scope of hypotheses
In the scientific hypothesis section, we defined the hypothesis and discussed how it relates back to the theory. In this section, we want to defend two claims about hypotheses:
- (A1) Hypotheses can have different scopes . Some hypotheses are narrower in their formulation, and some are broader.
- (A2) The scope of hypotheses can vary along three dimensions relating to relationship selection , variable selection , and pipeline selection .
A1 may seem obvious, but it is important to establish what is meant by narrower and broader scope. When a hypothesis is very narrow, it is specific. For example, it might be specific about the type of relationship between some variables. In figure 1 , we make four different statements regarding the relationship between x and y . The narrowest hypothesis here states ‘there is a positive linear relationship with a magnitude of 0.5 between x and y ’ ( figure 1 a ), and the broadest hypothesis states ‘there is a relationship between x and y ’ ( figure 1 d ). Note that many other hypotheses are possible that are not included in this example (such as there being no relationship).

Examples of narrow and broad hypotheses between x and y . Circles indicate a set of possible relationships with varying slopes that can pivot or bend.
We see that the narrowest of these hypotheses claims a type of relationship (linear), a direction of the relationship (positive) and a magnitude of the relationship (0.5). As the hypothesis becomes broader, the specific magnitude disappears ( figure 1 b ), the relationship has additional options than just being linear ( figure 1 c ), and finally, the direction of the relationship disappears. Crucially, all the examples in figure 1 can meet the above definition of scientific hypotheses. They are all statements that can be evaluated with the same scientific method. There is a difference between these statements, though— they differ in the scope of the hypothesis . Here we have justified A1.
Within this framework, when we discuss whether a hypothesis is narrower or broader in scope, this is a relation between two hypotheses where one is a subset of the other. This means that if H 1 is narrower than H 2 , and if H 1 is true, then H 2 is also true. This can be seen in figure 1 a–d . Suppose figure 1 a , the narrowest of all the hypotheses, is true. In that case, all the other broader statements are also true (i.e. a linear correlation of 0.5 necessarily entails that there is also a positive linear correlation, a linear correlation, and some relationship). While this property may appear trivial, it entails that it is only possible to directly compare the hypothesis scope between two hypotheses (i.e. their broadness or narrowness) where one is the subset of the other. 6
4.1. Sets, disjunctions and conjunctions of elements
The above restraint defines the scope as relations between sets. This property helps formalize the framework of this article. Below, when we discuss the different dimensions that can impact the scope, these become represented as a set. Each set contains elements. Each element is a permissible situation that allows the hypothesis to be accepted. We denote elements as lower case with italics (e.g. e 1 , e 2 , e 3 ) and sets as bold upper case (e.g. S ). Each of the three different dimensions discussed below will be formalized as sets, while the total number of elements specifies their scope.
Let us reconsider the above restraint about comparing hypotheses as narrower or broader. This can be formally shown if:
- e 1 , e 2 , e 3 are elements of S 1 ; and
- e 1 and e 2 are elements of S 2 ,
then S 2 is narrower than S 1 .
Each element represents specific propositions that, if corroborated, would support the hypothesis. Returning to figure 1 a , b , the following statements apply to both:
- ‘There is a positive linear relationship between x and y with a slope of 0.5’.
Whereas the following two apply to figure 1 b but not figure 1 a :
- ‘There is a positive linear relationship between x and y with a slope of 0.4’ ( figure 1 b ).
- ‘There is a positive linear relationship between x and y with a slope of 0.3’ ( figure 1 b ).
Figure 1 b allows for a considerably larger number of permissible situations (which is obvious as it allows for any positive linear relationship). When formulating the hypothesis in figure 1 b , we do not need to specify every single one of these permissible relationships. We can simply specify all possible positive slopes, which entails the set of permissible elements it includes.
That broader hypotheses have more elements in their sets entails some important properties. When we say S contains the elements e 1 , e 2 , and e 3 , the hypothesis is corroborated if e 1 or e 2 or e 3 is the case. This means that the set requires only one of the elements to be corroborated for the hypothesis to be considered correct (i.e. the positive linear relationship needs to be 0.3 or 0.4 or 0.5). Contrastingly, we will later see cases when conjunctions of elements occur (i.e. both e 1 and e 2 are the case). When a conjunction occurs, in this formulation, the conjunction itself becomes an element in the set (i.e. ‘ e 1 and e 2 ’ is a single element). Figure 2 illustrates how ‘ e 1 and e 2 ’ is narrower than ‘ e 1 ’, and ‘ e 1 ’ is narrower than ‘ e 1 or e 2 ’. 7 This property relating to the conjunction being narrower than individual elements is explained in more detail in the pipeline selection section below.

Scope as sets. Left : four different sets (grey, red, blue and purple) showing different elements which they contain. Right : a list of each colour explaining which set is a subset of the other (thereby being ‘narrower’).
4.2. Relationship selection
We move to A2, which is to show the different dimensions that a hypothesis scope can vary along. We have already seen an example of the first dimension of a hypothesis in figure 1 , the relationship selection . Let R denote the set of all possible configurations of relationships that are permissible for the hypothesis to be considered true. For example, in the narrowest formulation above, there was one allowed relationship for the hypothesis to be true. Consequently, the size of R (denoted | R |) is one. As discussed above, in the second narrowest formulation ( figure 1 b ), R has more possible relationships where it can still be considered true:
- r 1 = ‘a positive linear relationship of 0.1’
- r 2 = ‘a positive linear relationship of 0.2’
- r 3 = ‘a positive linear relationship of 0.3’.
Additionally, even broader hypotheses will be compatible with more types of relationships. In figure 1 c , d , nonlinear and negative relationships are also possible relationships included in R . For this broader statement to be affirmed, more elements are possible to be true. Thus if | R | is greater (i.e. contains more possible configurations for the hypothesis to be true), then the hypothesis is broader. Thus, the scope of relating to the relationship selection is specified by | R |. Finally, if |R H1 | > |R H2 | , then H 1 is broader than H 2 regarding the relationship selection.
Figure 1 is an example of the relationship narrowing. That the relationship became linear is only an example and does not necessitate a linear relationship or that this scope refers only to correlations. An alternative example of a relationship scope is a broad hypothesis where there is no knowledge about the distribution of some data. In such situations, one may assume a uniform relationship or a Cauchy distribution centred at zero. Over time the specific distribution can be hypothesized. Thereafter, the various parameters of the distribution can be hypothesized. At each step, the hypothesis of the distribution gets further specified to narrower formulations where a smaller set of possible relationships are included (see [ 47 , 48 ] for a more in-depth discussion about how specific priors relate to more narrow tests). Finally, while figure 1 was used to illustrate the point of increasingly narrow relationship hypotheses, it is more likely to expect the narrowest relationship, within fields such as psychology, to have considerable uncertainty and be formulated with confidence or credible intervals (i.e. we will rarely reach point estimates).
4.3. Variable selection
We have demonstrated that relationship selection can affect the scope of a hypothesis. Additionally, at least two other dimensions can affect the scope of a hypothesis: variable selection and pipeline selection . The variable selection in figure 1 was a single bivariate relationship (e.g. x 's relationship with y ). However, it is not always the case that we know which variables will be involved. For example, in neuroimaging, we can be confident that one or more brain regions will be processing some information following a stimulus. Still, we might not be sure which brain region(s) this will be. Consequently, our hypothesis becomes broader because we have selected more variables. The relationship selection may be identical for each chosen variable, but the variable selection becomes broader. We can consider the following three hypotheses to be increasing in their scope:
- H 1 : x relates to y with relationship R .
- H 2 : x 1 or x 2 relates to y with relationship R .
- H 3 : x 1 or x 2 or x 3 relates to y with relationship R .
For H 1 –H 3 above, we assume that R is the same. Further, we assume that there is no interaction between these variables.
In the above examples, we have multiple x ( x 1 , x 2 , x 3 , … , x n ). Again, we can symbolize the variable selection as a non-empty set XY , containing either a single variable or many variables. Our motivation for designating it XY is that the variable selection can include multiple possibilities for both the independent variable ( x ) and the dependent variable ( y ). Like with relationship selection, we can quantify the broadness between two hypotheses with the size of the set XY . Consequently, | XY | denotes the total scope concerning variable selection. Thus, in the examples above | XY H1 | < | XY H2 | < | XY H3 |. Like with relationship selection, hypotheses that vary in | XY | still meet the definition of a hypothesis. 8
An obvious concern for many is that a broader XY is much easier to evaluate as correct. Generally, when | XY 1 | > | XY 2 |, there is a greater chance of spurious correlations when evaluating XY 1 . This concern is an issue relating to the evaluation of hypotheses (e.g. applying statistics to the evaluation), which will require additional assumptions relating to how to evaluate the hypotheses. Strategies to deal with this apply some correction or penalization for multiple statistical testing [ 49 ] or partial pooling and regularizing priors [ 50 , 51 ]. These strategies aim to evaluate a broader variable selection ( x 1 or x 2 ) on equal or similar terms to a narrow variable selection ( x 1 ).
4.4. Pipeline selection
Scientific studies require decisions about how to perform the analysis. This scope considers transformations applied to the raw data ( XY raw ) to achieve some derivative ( XY ). These decisions can also involve selection procedures that drop observations deemed unreliable, standardizing, correcting confounding variables, or different philosophies. We can call the array of decisions and transformations used as the pipeline . A hypothesis varies in the number of pipelines:
- H 1 : XY has a relationship(s) R with pipeline p 1 .
- H 2 : XY has a relationship(s) R with pipeline p 1 or pipeline p 2 .
- H 3 : XY has a relationship(s) R with pipeline p 1 or pipeline p 2 , or pipeline p 3 .
Importantly, the pipeline here considers decisions regarding how the hypothesis shapes the data collection and transformation. We do not consider this to include decisions made regarding the assumptions relating to the statistical inference as those relate to operationalizing the evaluation of the hypothesis and not part of the hypothesis being evaluated (these assumptions are like auxiliary hypotheses, which are assumed to be true but not explicitly evaluated).
Like with variable selection ( XY ) and relationship selection ( R ), we can see that pipelines impact the scope of hypotheses. Again, we can symbolize the pipeline selection with a set P . As previously, | P | will denote the dimension of the pipeline selection. In the case of pipeline selection, we are testing the same variables, looking for the same relationship, but processing the variables or relationships with different pipelines to evaluate the relationship. Consequently, | P H1 | < | P H2 | < | P H3 |.
These issues regarding pipelines have received attention as the ‘garden of forking paths' [ 52 ]. Here, there are calls for researchers to ensure that their entire pipeline has been specified. Additionally, recent work has highlighted the diversity of results based on multiple analytical pipelines [ 53 , 54 ]. These results are often considered a concern, leading to calls that results should be pipeline resistant.
The wish for pipeline-resistant methods entails that hypotheses, in their narrowest form, are possible for all pipelines. Consequently, a narrower formulation will entail that this should not impact the hypothesis regardless of which pipeline is chosen. Thus the conjunction of pipelines is narrower than single pipelines. Consider the following three scenarios:
- H 3 : XY has a relationship(s) R with pipeline p 1 and pipeline p 2 .
In this instance, since H 1 is always true if H 3 is true, thus H 3 is a narrower formulation than H 1 . Consequently, | P H3 | < | P H1 | < | P H2 |. Decreasing the scope of the pipeline dimension also entails the increase in conjunction of pipelines (i.e. creating pipeline-resistant methods) rather than just the reduction of disjunctional statements.
4.5. Combining the dimensions
In summary, we then have three different dimensions that independently affect the scope of the hypothesis. We have demonstrated the following general claim regarding hypotheses:
- The variables XY have a relationship R with pipeline P .
And that the broadness and narrowness of a hypothesis depend on how large the three sets XY , R and P are. With this formulation, we can conclude that hypotheses have a scope that can be determined with a 3-tuple argument of (| R |, | XY |, | P |).
While hypotheses can be formulated along these three dimensions and generally aim to be reduced, it does not entail that these dimensions behave identically. For example, the relationship dimensions aim to reduce the number of elements as far as possible (e.g. to an interval). Contrastingly, for both variables and pipeline, the narrower hypothesis can reduce to single variables/pipelines or become narrower still and become conjunctions where all variables/pipelines need to corroborate the hypothesis (i.e. regardless of which method one follows, the hypothesis is correct).
5. Additional possible dimensions
No commitment is being made about the exhaustive nature of there only being three dimensions that specify the hypothesis scope. Other dimensions may exist that specify the scope of a hypothesis. For example, one might consider the pipeline dimension as two different dimensions. The first would consider the experimental pipeline dimension regarding all variables relating to the experimental setup to collect data, and the latter would be the analytical pipeline dimension regarding the data analysis of any given data snapshot. Another possible dimension is adding the number of situations or contexts under which the hypothesis is valid. For example, any restraint such as ‘in a vacuum’, ‘under the speed of light’, or ‘in healthy human adults' could be considered an additional dimension of the hypothesis. There is no objection to whether these should be additional dimensions of the hypothesis. However, as stated above, these usually follow from the boundary conditions of the theory.
6. Specifying the scope versus assumptions
We envision that this framework can help hypothesis-makers formulate hypotheses (in research plans, registered reports, preregistrations etc.). Further, using this framework while formulating hypotheses can help distinguish between auxiliary hypotheses and parts of the scientific hypothesis being tested. When writing preregistrations, it can frequently occur that some step in the method has two alternatives (e.g. a preprocessing step), and there is not yet reason to choose one over the other, and the researcher needs to make a decision. These following scenarios are possible:
- 1. Narrow pipeline scope . The researcher evaluates the hypothesis with both pipeline variables (i.e. H holds for both p 1 and p 2 where p 1 and p 2 can be substituted with each other in the pipeline).
- 2. Broad pipeline scope. The researcher evaluates the hypothesis with both pipeline variables, and only one needs to be correct (i.e. H holds for either p 1 or p 2 where p 1 and p 2 can be substituted with each other in the pipeline). The result of this experiment may help motivate choosing either p 1 or p 2 in future studies.
- 3. Auxiliary hypothesis. Based on some reason (e.g. convention), the researcher assumes p 1 and evaluates H assuming p 1 is true.
Here we see that the same pipeline step can be part of either the auxiliary hypotheses or the pipeline scope. This distinction is important because if (3) is chosen, the decision becomes an assumption that is not explicitly tested by the hypothesis. Consequently, a researcher confident in the hypothesis may state that the auxiliary hypothesis p 1 was incorrect, and they should retest their hypothesis using different assumptions. In the cases where this decision is part of the pipeline scope, the hypothesis is intertwined with this decision, removing the eventual wiggle-room to reject auxiliary hypotheses that were assumed. Furthermore, starting with broader pipeline hypotheses that gradually narrow down can lead to a more well-motivated protocol for approaching the problem. Thus, this framework can help researchers while writing their hypotheses in, for example, preregistrations because they can consider when they are committing to a decision, assuming it, or when they should perhaps test a broader hypothesis with multiple possible options (discussed in more detail in §11 below).
7. The reduction of scope in hypothesis space
Having established that different scopes of a hypothesis are possible, we now consider how the hypotheses change over time. In this section, we consider how the scope of the hypothesis develops ideally within science.
Consider a new research question. A large number of hypotheses are possible. Let us call this set of all possible hypotheses the hypothesis space . Hypotheses formulated within this space can be narrower or broader based on the dimensions discussed previously ( figure 3 ).

Example of hypothesis space. The hypothesis scope is expressed as cuboids in three dimensions (relationship ( R ), variable ( XY ), pipeline ( P )). The hypothesis space is the entire possible space within the three dimensions. Three hypotheses are shown in the hypothesis space (H 1 , H 2 , H 3 ). H 2 and H 3 are subsets of H 1 .
After the evaluation of the hypothesis with the scientific process, the hypothesis will be accepted or rejected. 9 The evaluation could be done through falsification or via verification, depending on the philosophy of science commitments. Thereafter, other narrower formulations of the hypothesis can be formulated by reducing the relationship, variable or pipeline scope. If a narrower hypothesis is accepted, more specific details about the subject matter are known, or a theory has been refined in greater detail. A narrower hypothesis will entail a more specific relationship, variable or pipeline detailed in the hypothesis. Consequently, hypotheses linked to each other in this way will become narrower over time along one or more dimensions. Importantly, considering that the conjunction of elements is narrower than single elements for pipelines and variables, this process of narrower hypotheses will lead to more general hypotheses (i.e. they have to be applied in all conditions and yield less flexibility when they do not apply). 10
Considering that the scopes of hypotheses were defined as sets above, some properties can be deduced from this framework about how narrower hypotheses relate to broader hypotheses. Let us consider three hypotheses (H 1 , H 2 , and H 3 ; figure 3 ). H 2 and H 3 are non-overlapping subsets of H 1 . Thus H 2 and H 3 are both narrower in scope than H 1 . Thus the following is correct:
- P1: If H 1 is false, then H 2 is false, and H 2 does not need to be evaluated.
- P2: If H 2 is true, then the broader H 1 is true, and H 1 does not need to be evaluated.
- P3: If H 1 is true and H 2 is false, some other hypothesis H 3 of similar scope to H 2 is possible.
For example, suppose H 1 is ‘there is a relationship between x and y ’, H 2 is ‘there is a positive relationship between x and y ’, and H 3 is ‘a negative relationship between x and y ’. In that case, it becomes apparent how each of these follows. 11 Logically, many deductions from set theory are possible but will not be explored here. Instead, we will discuss two additional consequences of hypothesis scopes: scientific novelty and applications for the researcher who formulates a hypothesis.
P1–P3 have been formulated as hypotheses being true or false. In practice, hypotheses are likely evaluated probabilistically (e.g. ‘H 1 is likely’ or ‘there is evidence in support of H 1 ’). In these cases, P1–P3 can be rephrased to account for this by substituting true/false with statements relating to evidence. For example, P2 could read: ‘If there is evidence in support of H 2 , then there is evidence in support of H 1 , and H 1 does not need to be evaluated’.
8. Scientific novelty as the reduction of scope
Novelty is a key concept that repeatedly occurs in multiple aspects of the scientific enterprise, from funding to publishing [ 55 ]. Generally, scientific progress establishes novel results based on some new hypothesis. Consequently, the new hypothesis for the novel results must be narrower than previously established knowledge (i.e. the size of the scopes is reduced). Otherwise, the result is trivial and already known (see P2 above). Thus, scientific work is novel if the scientific process produces a result based on hypotheses with either a smaller | R |, | XY |, or | P | compared to previous work.
This framework of dimensions of the scope of a hypothesis helps to demarcate when a hypothesis and the subsequent result are novel. If previous studies have established evidence for R 1 (e.g. there is a positive relationship between x and y ), a hypothesis will be novel if and only if it is narrower than R 1 . Thus, if R 2 is narrower in scope than R 1 (i.e. | R 2 | < | R 1 |), R 2 is a novel hypothesis.
Consider the following example. Study 1 hypothesizes, ‘There is a positive relationship between x and y ’. It identifies a linear relationship of 0.6. Next, Study 2 hypothesizes, ‘There is a specific linear relationship between x and y that is 0.6’. Study 2 also identifies the relationship of 0.6. Since this was a narrower hypothesis, Study 2 is novel despite the same result. Frequently, researchers claim that they are the first to demonstrate a relationship. Being the first to demonstrate a relationship is not the final measure of novelty. Having a narrower hypothesis than previous researchers is a sign of novelty as it further reduces the hypothesis space.
Finally, it should be noted that novelty is not the only objective of scientific work. Other attributes, such as improving the certainty of a current hypothesis (e.g. through replications), should not be overlooked. Additional scientific explanations and improved theories are other aspects. Additionally, this definition of novelty relating to hypothesis scope does not exclude other types of novelty (e.g. new theories or paradigms).
9. How broad should a hypothesis be?
Given the previous section, it is elusive to conclude that the hypothesis should be as narrow as possible as it entails maximal knowledge gain and scientific novelty when formulating hypotheses. Indeed, many who advocate for daring or risky tests seem to hold this opinion. For example, Meehl [ 46 ] argues that we should evaluate theories based on point (or interval) prediction, which would be compatible with very narrow versions of relationships. We do not necessarily think that this is the most fruitful approach. In this section, we argue that hypotheses should aim to be narrower than current knowledge , but too narrow may be problematic .
Let us consider the idea of confirmatory analyses. These studies will frequently keep the previous hypothesis scopes regarding P and XY but aim to become more specific regarding R (i.e. using the same method and the same variables to detect a more specific relationship). A very daring or narrow hypothesis is to minimize R to include the fewest possible relationships. However, it becomes apparent that simply pursuing specificness or daringness is insufficient for selecting relevant hypotheses. Consider a hypothetical scenario where a researcher believes virtual reality use leads people to overestimate the amount of exercise they have done. If unaware of previous studies on this project, an apt hypothesis is perhaps ‘increased virtual reality usage correlates with a less accuracy of reported exercise performed’ (i.e. R is broad). However, a more specific and more daring hypothesis would be to specify the relationship further. Thus, despite not knowing if there is a relationship at all, a more daring hypothesis could be: ‘for every 1 h of virtual reality usage, there will be, on average, a 0.5% decrease in the accuracy of reported exercise performed’ (i.e. R is narrow). We believe it would be better to establish the broader hypothesis in any scenario here for the first experiment. Otherwise, if we fail to confirm the more specific formulation, we could reformulate another equally narrow relative to the broader hypothesis. This process of tweaking a daring hypothesis could be pursued ad infinitum . Such a situation will neither quickly identify the true hypothesis nor effectively use limited research resources.
By first discounting a broader hypothesis that there is no relationship, it will automatically discard all more specific formulations of that relationship in the hypothesis space. Returning to figure 3 , it will be better to establish H 1 before attempting H 2 or H 3 to ensure the correct area in the hypothesis space is being investigated. To provide an analogy: when looking for a needle among hay, first identify which farm it is at, then which barn, then which haystack, then which part of the haystack it is at before we start picking up individual pieces of hay. Thus, it is preferable for both pragmatic and cost-of-resource reasons to formulate sufficiently broad hypotheses to navigate the hypothesis space effectively.
Conversely, formulating too broad a relationship scope in a hypothesis when we already have evidence for narrower scope would be superfluous research (unless the evidence has been called into question by, for example, not being replicated). If multiple studies have supported the hypothesis ‘there is a 20-fold decrease in mortality after taking some medication M’, it would be unnecessary to ask, ‘Does M have any effect?’.
Our conclusion is that the appropriate scope of a hypothesis, and its three dimensions, follow a Goldilocks-like principle where too broad is superfluous and not novel, while too narrow is unnecessary or wasteful. Considering the scope of one's hypothesis and how it relates to previous hypotheses' scopes ensures one is asking appropriate questions.
Finally, there has been a recent trend in psychology that hypotheses should be formal [ 38 , 56 – 60 ]. Formal theories are precise since they are mathematical formulations entailing that their interpretations are clear (non-ambiguous) compared to linguistic theories. However, this literature on formal theories often refers to ‘precise predictions’ and ‘risky testing’ while frequently referencing Meehl, who advocates for narrow hypotheses (e.g. [ 38 , 56 , 59 ]). While perhaps not intended by any of the proponents, one interpretation of some of these positions is that hypotheses derived from formal theories will be narrow hypotheses (i.e. the quality of being ‘precise’ can mean narrow hypotheses with risky tests and non-ambiguous interpretations simultaneously). However, the benefit from the clarity (non-ambiguity) that formal theories/hypotheses bring also applies to broad formal hypotheses as well. They can include explicit but formalized versions of uncertain relationships, multiple possible pipelines, and large sets of variables. For example, a broad formal hypothesis can contain a hyperparameter that controls which distribution the data fit (broad relationship scope), or a variable could represent a set of formalized explicit pipelines (broad pipeline scope) that will be tested. In each of these instances, it is possible to formalize non-ambiguous broad hypotheses from broad formal theories that do not yet have any justification for being overly narrow. In sum, our argumentation here stating that hypotheses should not be too narrow is not an argument against formal theories but rather that hypotheses (derived from formal theories) do not necessarily have to be narrow.
10. Other approaches to categorizing hypotheses
The framework we present here is a way of categorizing hypotheses into (at least) three dimensions regarding the hypothesis scope, which we believe is accessible to researchers and help link scientific work over time while also trying to remain neutral with regard to a specific philosophy of science. Our proposal does not aim to be antagonistic or necessarily contradict other categorizing schemes—but we believe that our framework provides benefits.
One recent categorization scheme is the Theoretical (T), Auxiliary (A), Statistical (S) and Inferential (I) assumption model (together becoming the TASI model) [ 61 , 62 ]. Briefly, this model considers theory to generate theoretical hypotheses. To translate from theoretical unobservable terms (e.g. personality, anxiety, mass), auxiliary assumptions are needed to generate an empirical hypothesis. Statistical assumptions are often needed to test the empirical hypothesis (e.g. what is the distribution, is it skewed or not) [ 61 , 62 ]. Finally, additional inferential assumptions are needed to generalize to a larger population (e.g. was there a random and independent sampling from defined populations). The TASI model is insightful and helpful in highlighting the distance between a theory and the observation that would corroborate/contradict it. Part of its utility is to bring auxiliary hypotheses into the foreground, to improve comparisons between studies and improve theory-based interventions [ 63 , 64 ].
We do agree with the importance of being aware of or stating the auxiliary hypotheses, but there are some differences between the frameworks. First, the number of auxiliary assumptions in TASI can be several hundred [ 62 ], whereas our framework will consider some of them as part of the pipeline dimension. Consider the following four assumptions: ‘the inter-stimulus interval is between 2000 ms and 3000 ms', ‘the data will be z-transformed’, ‘subjects will perform correctly’, and ‘the measurements were valid’. According to the TASI model, all these will be classified similarly as auxiliary assumptions. Contrarily, within our framework, it is possible to consider the first two as part of the pipeline dimension and the latter two as auxiliary assumptions, and consequently, the first two become integrated as part of the hypothesis being tested and the latter two auxiliary assumptions. A second difference between the frameworks relates to non-theoretical studies (convenience, applied or atheoretical). Our framework allows for the possibility that the hypothesis space generated by theoretical and convenience studies can interact and inform each other within the same framework . Contrarily, in TASI, the theory assumptions no longer apply, and a different type of hypothesis model is needed; these assumptions must be replaced by another group of assumptions (where ‘substantive application assumptions' replace the T and the A, becoming SSI) [ 61 ]. Finally, part of our rationale for our framework is to be able to link and track hypotheses and hypothesis development together over time, so our classification scheme has different utility.
Another approach which has some similar utility to this framework is theory construction methodology (TCM) [ 57 ]. The similarity here is that TCM aims to be a practical guide to improve theory-making in psychology. It is an iterative process which relates theory, phenomena and data. Here hypotheses are not an explicit part of the model. However, what is designated as ‘proto theory’ could be considered a hypothesis in our framework as they are a product of abduction, shaping the theory space. Alternatively, what is deduced to evaluate the theory can also be considered a hypothesis. We consider both possible and that our framework can integrate with these two steps, especially since TCM does not have clear guidelines for how to do each step.
11. From theory to practice: implementing this framework
We believe that many practising researchers can relate to many aspects of this framework. But, how can a researcher translate the above theoretical framework to their work? The utility of this framework lies in bringing these three scopes of a hypothesis together and explaining how each can be reduced. We believe researchers can use this framework to describe their current practices more clearly. Here we discuss how it can be helpful for researchers when formulating, planning, preregistering, and discussing the evaluation of their scientific hypotheses. These practical implications are brief, and future work can expand on the connection between the full interaction between hypothesis space and scope. Furthermore, both authors have the most experience in cognitive neuroscience, and some of the practical implications may revolve around this type of research and may not apply equally to other fields.
11.1. Helping to form hypotheses
Abduction, according to Peirce, is a hypothesis-making exercise [ 22 , 26 – 28 ]. Given some observations, a general testable explanation of the phenomena is formed. However, when making the hypothesis, this statement will have a scope (either explicitly or implicitly). Using our framework, the scope can become explicit. The hypothesis-maker can start with ‘The variables XY have a relationship R with pipeline P ’ as a scaffold to form the hypothesis. From here, the hypothesis-maker can ‘fill in the blanks’, explicitly adding each of the scopes. Thus, when making a hypothesis via abduction and using our framework, the hypothesis will have an explicit scope when it is made. By doing this, there is less chance that a formulated hypothesis is unclear, ambiguous, and needs amending at a later stage.
11.2. Assisting to clearly state hypotheses
A hypothesis is not just formulated but also communicated. Hypotheses are stated in funding applications, preregistrations, registered reports, and academic articles. Further, preregistered hypotheses are often omitted or changed in the final article [ 11 ], and hypotheses are not always explicitly stated in articles [ 12 ]. How can this framework help to make better hypotheses? Similar to the previous point, filling in the details of ‘The variables XY have a relationship R with pipeline P ’ is an explicit way to communicate the hypothesis. Thinking about each of these dimensions should entail an appropriate explicit scope and, hopefully, less variation between preregistered and reported hypotheses. The hypothesis does not need to be a single sentence, and details of XY and P will often be developed in the methods section of the text. However, using this template as a starting point can help ensure the hypothesis is stated, and the scope of all three dimensions has been communicated.
11.3. Helping to promote explicit and broad hypotheses instead of vague hypotheses
There is an important distinction between vague hypotheses and broad hypotheses, and this framework can help demarcate between them. A vague statement would be: ‘We will quantify depression in patients after treatment’. Here there is uncertainty relating to how the researcher will go about doing the experiment (i.e. how will depression be quantified?). However, a broad statement can be uncertain, but the uncertainty is part of the hypothesis: ‘Two different mood scales (S 1 or S 2 ) will be given to patients and test if only one (or both) changed after treatment’. This latter statement is transparently saying ‘S 1 or S 2 ’ is part of a broad hypothesis—the uncertainty is whether the two different scales are quantifying the same construct. We keep this uncertainty within the broad hypothesis, which will get evaluated, whereas a vague hypothesis has uncertainty as part of the interpretation of the hypothesis. This framework can be used when formulating hypotheses to help be broad (where needed) but not vague.
11.4. Which hypothesis should be chosen?
When considering the appropriate scope above, we argued for a Goldilocks-like principle of determining the hypothesis that is not too broad or too narrow. However, when writing, for example, a preregistration, how does one identify this sweet spot? There is no easy or definite universal answer to this question. However, one possible way is first to identify the XY , R , and P of previous hypotheses. From here, identify what a non-trivial step is to improve our knowledge of the research area. So, for example, could you be more specific about the exact nature of the relationship between the variables? Does the pipeline correspond to today's scientific standards, or were some suboptimal decisions made? Is there another population that you think the previous result also applies to? Do you think that maybe a more specific construct or subpopulation might explain the previous result? Could slightly different constructs (perhaps easier to quantify) be used to obtain a similar relationship? Are there even more constructs to which this relationship should apply simultaneously? Are you certain of the direction of the relationship? Answering affirmatively to any of these questions will likely make a hypothesis narrower and connect to previous research while being clear and explicit. Moreover, depending on the research question, answering any of these may be sufficiently narrow to be a non-trivial innovation. However, there are many other ways to make a hypothesis narrower than these guiding questions.
11.5. The confirmatory–exploratory continuum
Research is often dichotomized into confirmatory (testing a hypothesis) or exploratory (without a priori hypotheses). With this framework, researchers can consider how their research acts on some hypothesis space. Confirmatory and exploratory work has been defined in terms of how each interacts with the researcher's degrees of freedom (where confirmatory aims to reduce while exploratory utilizes them [ 30 ]). Both broad confirmatory and narrow exploratory research are possible using this definition and possible within this framework. How research interacts with the hypothesis space helps demarcate it. For example, if a hypothesis reduces the scope, it becomes more confirmatory, and trying to understand data given the current scope would be more exploratory work. This further could help demarcate when exploration is useful. Future theoretical work can detail how different types of research impact the hypothesis space in more detail.
11.6. Understanding when multiverse analyses are needed
Researchers writing a preregistration may face many degrees of freedom they have to choose from, and different researchers may motivate different choices. If, when writing such a preregistration, there appears to be little evidential support for certain degrees of freedom over others, the researcher is left with the option to either make more auxiliary assumptions or identify when an investigation into the pipeline scope is necessary by conducting a multiverse analysis that tests the impact of the different degrees of freedom on the result (see [ 8 ]). Thus, when applying this framework to explicitly state what pipeline variables are part of the hypothesis or an auxiliary assumption, the researcher can identify when it might be appropriate to conduct a multiverse analysis because they are having difficulty formulating hypotheses.
11.7. Describing novelty
Academic journals and research funders often ask for novelty, but the term ‘novelty’ can be vague and open to various interpretations [ 55 ]. This framework can be used to help justify the novelty of research. For example, consider a scenario where a previous study has established a psychological construct (e.g. well-being) that correlates with a certain outcome measure (e.g. long-term positive health outcomes). This framework can be used to explicitly justify novelty by (i) providing a more precise understanding of the relationship (e.g. linear or linear–plateau) or (ii) identifying more specific variables related to well-being or health outcomes. Stating how some research is novel is clearer than merely stating that the work is novel. This practice might even help journals and funders identify what type of novelty they would like to reward. In sum, this framework can help identify and articulate how research is novel.
11.8. Help to identify when standardization of pipelines is beneficial or problematic to a field
Many consider standardization in a field to be important for ensuring the comparability of results. Standardization of methods and tools entails that the pipeline P is identical (or at least very similar) across studies. However, in such cases, the standardized pipeline becomes an auxiliary assumption representing all possible pipelines. Therefore, while standardized pipelines have their benefits, this assumption becomes broader without validating (e.g. via multiverse analysis) which pipelines a standardized P represents. In summary, because this framework helps distinguish between auxiliary assumptions and explicit parts of the hypothesis and identifies when a multiverse analysis is needed, it can help determine when standardizations of pipelines are representative (narrower hypotheses) or assumptive (broader hypotheses).
12. Conclusion
Here, we have argued that the scope of a hypothesis is made up of three dimensions: the relationship ( R ), variable ( XY ) and pipeline ( P ) selection. Along each of these dimensions, the scope can vary. Different types of scientific enterprises will often have hypotheses that vary the size of the scopes. We have argued that this focus on the scope of the hypothesis along these dimensions helps the hypothesis-maker formulate their hypotheses for preregistrations while also helping demarcate auxiliary hypotheses (assumed to be true) from the hypothesis (those being evaluated during the scientific process).
Hypotheses are an essential part of the scientific process. Considering what type of hypothesis is sufficient or relevant is an essential job of the researcher that we think has been overlooked. We hope this work promotes an understanding of what a hypothesis is and how its formulation and reduction in scope is an integral part of scientific progress. We hope it also helps clarify how broad hypotheses need not be vague or inappropriate.
Finally, we applied this idea of scopes to scientific progress and considered how to formulate an appropriate hypothesis. We have also listed several ways researchers can practically implement this framework today. However, there are other practicalities of this framework that future work should explore. For example, it could be used to differentiate and demarcate different scientific contributions (e.g. confirmatory studies, exploration studies, validation studies) with how their hypotheses interact with the different dimensions of the hypothesis space. Further, linking hypotheses over time within this framework can be a foundation for open hypothesis-making by promoting explicit links to previous work and detailing the reduction of the hypothesis space. This framework helps quantify the contribution to the hypothesis space of different studies and helps clarify what aspects of hypotheses can be relevant at different times.
Acknowledgements
We thank Filip Gedin, Kristoffer Sundberg, Jens Fust, and James Steele for valuable feedback on earlier versions of this article. We also thank Mark Rubin and an unnamed reviewer for valuable comments that have improved the article.
1 While this is our intention, we cannot claim that every theory has been accommodated.
2 Similar requirements of science being able to evaluate the hypothesis can be found in pragmatism [ 22 ], logical positivism [ 23 ] and falsification [ 24 ].
3 Although when making inferences about a failed evaluation of a scientific hypothesis it is possible, due to underdetermination, to reject the auxiliary hypothesis instead of rejecting the hypothesis. However, that rejection occurs at a later inference stage. The evaluation using the scientific method aims to test the scientific hypothesis, not the auxiliary assumptions.
4 Although some have argued that this practice is not as problematic or questionable (see [ 34 , 35 ]).
5 Alternatively, theories sometimes expand their boundary conditions. A theory that was previously about ‘humans' can be used with a more inclusive boundary condition. Thus it is possible for the hypothesis-maker to use a theory about humans (decision making) and expand it to fruit flies or plants (see [ 43 ]).
6 A similarity exists here with Popper, where he uses set theory in a similar way to compare theories (not hypotheses). Popper also discusses how theories with overlapping sets but neither is a subset are also comparable (see [ 24 , §§32–34]). We do not exclude this possibility but can require additional assumptions.
7 When this could be unclear, we place the element within quotation marks.
8 Here, we have assumed that there is no interaction between these variables in variable selection. If an interaction between x 1 and x 2 is hypothesized, this should be viewed as a different variable compared to ‘ x 1 or x 2 ’. The motivation behind this is because the hypothesis ‘ x 1 or x 2 ’ is not a superset of the interaction (i.e. ‘ x 1 or x 2 ’ is not necessarily true when the interaction is true). The interaction should, in this case, be considered a third variable (e.g. I( x 1 , x 2 )) and the hypothesis ‘ x 1 or x 2 or I( x 1 , x 2 )’ is broader than ‘ x 1 or x 2 ’.
9 Or possibly ambiguous or inconclusive.
10 This formulation of scope is compatible with different frameworks from the philosophy of science. For example, by narrowing the scope would in a Popperian terminology mean prohibiting more basic statements (thus a narrower hypothesis has a higher degree of falsifiability). The reduction of scope in the relational dimension would in Popperian terminology mean increase in precision (e.g. a circle is more precise than an ellipse since circles are a subset of possible ellipses), whereas reduction in variable selection and pipeline dimension would mean increase universality (e.g. ‘all heavenly bodies' is more universal than just ‘planets') [ 24 ]. For Meehl the reduction of the relationship dimension would amount to decreasing the relative tolerance of a theory to the Spielraum [ 46 ] .
11 If there is no relationship between x and y , we do not need to test if there is a positive relationship. If we know there is a positive relationship between x and y , we do not need to test if there is a relationship. If we know there is a relationship but there is not a positive relationship, then it is possible that they have a negative relationship.
Data accessibility
Declaration of ai use.
We have not used AI-assisted technologies in creating this article.
Authors' contributions
W.H.T.: conceptualization, investigation, writing—original draft, writing—review and editing; S.S.: investigation, writing—original draft, writing—review and editing.
Both authors gave final approval for publication and agreed to be held accountable for the work performed therein.
Conflict of interest declaration
We declare we have no competing interests.
We received no funding for this study.

Writing for Computer Science pp 35–49 Cite as
Hypotheses, Questions, and Evidence
- Justin Zobel 2
- First Online: 01 January 2015
15k Accesses
The first stages of a research program involve choice of interesting topics or problems, and then identification of particular issues to investigate. The research is given direction by development of specific questions that the program aims to answer. These questions are based on an understanding—an informal model, perhaps—of how something works, or interacts, or behaves. They establish a framework for making observations about the object being studied. This framework can be characterised as a statement of belief about how the object behaves—in other words, a hypothesis .
- Swimming Pool
- Text Indexing
- Machine Translation System
- Reduce Wait Time
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
The intensity of the conviction that a hypothesis is true has no bearing on whether it is true or not. P.B. Medawar Advice to a Young Scientist The great tragedy of Science, the slaying of a beautiful hypothesis by an ugly fact. T.H. Huxley Biogenesis and Abiogenesis An argument is a connected series of statements intended to establish a proposition ... Argument is an intellectual process. Contradiction is just the automatic gainsaying of anything the other person says. Monty Python The Argument Sketch
This is a preview of subscription content, log in via an institution .
Buying options
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Which can, of course, lead to the discovery that the theorem is wrong after all.
An example of pseudoscience in computing are schemes for high-performance video compression that promised delivery of TV-quality data over low-bandwidth modems. In the 1990s, the commercial implications of such systems were enormous, and this incentive created ample opportunities for fraud. In one case, for example, millions of dollars were scammed from investors with tricks such as hiding a video player inside a PC tower and hiding a network cable inside a power cable. Yet, skeptically considered, such schemes are implausible. For example, with current technology, even a corner of a single TV-resolution image—let alone 25 frames—cannot be compressed into the 7 kilobytes that such a modem could transmit per second. Uncompressed, the bandwidth of a modem was only sufficient for one byte per row per image, or, per image, about the space needed to transmit a desktop icon. A further skeptical consideration in this case was that an audio signal was also transmitted. Had the system been legitimate, the inventor must have developed new solutions to the independent problems of image compression, motion encoding, and audio compression.
In another variant of this theme, objects of the same type were clustered together using some kind of similarity metric. Then the patterns of clustering were analyzed, and objects that clustered in similar ways were supposed to have similar subject matter. Although it is disguised by the use of clustering, to be successful such an approach assumes an underlying universal matching method.
An interesting question is how to regard “Zipf’s law”. This observation—“law” seems a poor choice of terminology in this context—is if nothing else a curious case study. Zipf’s books may be widely cited but they are not, I suspect, widely read. In Human Behaviour and the Principle of Least Effort (Addison-Wesley, 1949), Zipf used languages and word frequencies as one of several examples to illustrate his observation, but his motivation for the work is not quite what might be expected. He states, for example, that his research “define[s] objectively what we mean by the term personality” (p. 18), explains the “drives of the Freudian death wish” (p. 17), and “will provide an objective language in terms of which persons can discuss social problems impersonally” (p. 543). It “will help to protect mankind from the virtual criminal action of persons in strategic political, commercial, social, intellectual and academic positions” (p. 544) and “as the authority of revealed religion and its attendant ethics declines, something must take its place ... I feel that this type of research may yield results that will fulfill those needs” (p. 544). Perhaps these extraordinary claims are quirks, and in any case opinions do not invalidate scientific results. But it has been argued that the behaviour captured by Zipf’s conjecture is a simple consequence of randomness, and, for the example for which the conjecture is often cited (distribution of words in text), the fit between hypothesis and observation is not always strong.
Two philosophers are arguing in a bar. The barman goes over to them and asks, “What are you arguing about?”
“We’re debating whether computer science is a science”, answers one of them.
“And what do you conclude?” asks the barman.
“We’re not sure yet,” says the other. “We can’t agree on what ‘is’ means”.
But, in fairness, the views here have the same limitations, as they are those of a computer scientist who believes that the discipline stands alongside the traditional sciences.
Author information
Authors and affiliations.
Department of Computing and Information Systems, The University of Melbourne, Parkville, VIC, Australia
Justin Zobel
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Justin Zobel .
Rights and permissions
Reprints and permissions
Copyright information
© 2014 Springer-Verlag London
About this chapter
Cite this chapter.
Zobel, J. (2014). Hypotheses, Questions, and Evidence. In: Writing for Computer Science. Springer, London. https://doi.org/10.1007/978-1-4471-6639-9_4
Download citation
DOI : https://doi.org/10.1007/978-1-4471-6639-9_4
Published : 10 February 2015
Publisher Name : Springer, London
Print ISBN : 978-1-4471-6638-2
Online ISBN : 978-1-4471-6639-9
eBook Packages : Computer Science Computer Science (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- Search Search Please fill out this field.
- Fundamental Analysis
Hypothesis to Be Tested: Definition and 4 Steps for Testing with Example
:max_bytes(150000):strip_icc():format(webp)/ChristinaMajaski-5c9433ea46e0fb0001d880b1.jpeg "hypothesis keywords")
What Is Hypothesis Testing?
Hypothesis testing, sometimes called significance testing, is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used and the reason for the analysis.
Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data. Such data may come from a larger population, or from a data-generating process. The word "population" will be used for both of these cases in the following descriptions.
Key Takeaways
- Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data.
- The test provides evidence concerning the plausibility of the hypothesis, given the data.
- Statistical analysts test a hypothesis by measuring and examining a random sample of the population being analyzed.
- The four steps of hypothesis testing include stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
How Hypothesis Testing Works
In hypothesis testing, an analyst tests a statistical sample, with the goal of providing evidence on the plausibility of the null hypothesis.
Statistical analysts test a hypothesis by measuring and examining a random sample of the population being analyzed. All analysts use a random population sample to test two different hypotheses: the null hypothesis and the alternative hypothesis.
The null hypothesis is usually a hypothesis of equality between population parameters; e.g., a null hypothesis may state that the population mean return is equal to zero. The alternative hypothesis is effectively the opposite of a null hypothesis (e.g., the population mean return is not equal to zero). Thus, they are mutually exclusive , and only one can be true. However, one of the two hypotheses will always be true.
The null hypothesis is a statement about a population parameter, such as the population mean, that is assumed to be true.
4 Steps of Hypothesis Testing
All hypotheses are tested using a four-step process:
- The first step is for the analyst to state the hypotheses.
- The second step is to formulate an analysis plan, which outlines how the data will be evaluated.
- The third step is to carry out the plan and analyze the sample data.
- The final step is to analyze the results and either reject the null hypothesis, or state that the null hypothesis is plausible, given the data.
Real-World Example of Hypothesis Testing
If, for example, a person wants to test that a penny has exactly a 50% chance of landing on heads, the null hypothesis would be that 50% is correct, and the alternative hypothesis would be that 50% is not correct.
Mathematically, the null hypothesis would be represented as Ho: P = 0.5. The alternative hypothesis would be denoted as "Ha" and be identical to the null hypothesis, except with the equal sign struck-through, meaning that it does not equal 50%.
A random sample of 100 coin flips is taken, and the null hypothesis is then tested. If it is found that the 100 coin flips were distributed as 40 heads and 60 tails, the analyst would assume that a penny does not have a 50% chance of landing on heads and would reject the null hypothesis and accept the alternative hypothesis.
If, on the other hand, there were 48 heads and 52 tails, then it is plausible that the coin could be fair and still produce such a result. In cases such as this where the null hypothesis is "accepted," the analyst states that the difference between the expected results (50 heads and 50 tails) and the observed results (48 heads and 52 tails) is "explainable by chance alone."
Some staticians attribute the first hypothesis tests to satirical writer John Arbuthnot in 1710, who studied male and female births in England after observing that in nearly every year, male births exceeded female births by a slight proportion. Arbuthnot calculated that the probability of this happening by chance was small, and therefore it was due to “divine providence.”
What is Hypothesis Testing?
Hypothesis testing refers to a process used by analysts to assess the plausibility of a hypothesis by using sample data. In hypothesis testing, statisticians formulate two hypotheses: the null hypothesis and the alternative hypothesis. A null hypothesis determines there is no difference between two groups or conditions, while the alternative hypothesis determines that there is a difference. Researchers evaluate the statistical significance of the test based on the probability that the null hypothesis is true.
What are the Four Key Steps Involved in Hypothesis Testing?
Hypothesis testing begins with an analyst stating two hypotheses, with only one that can be right. The analyst then formulates an analysis plan, which outlines how the data will be evaluated. Next, they move to the testing phase and analyze the sample data. Finally, the analyst analyzes the results and either rejects the null hypothesis or states that the null hypothesis is plausible, given the data.
What are the Benefits of Hypothesis Testing?
Hypothesis testing helps assess the accuracy of new ideas or theories by testing them against data. This allows researchers to determine whether the evidence supports their hypothesis, helping to avoid false claims and conclusions. Hypothesis testing also provides a framework for decision-making based on data rather than personal opinions or biases. By relying on statistical analysis, hypothesis testing helps to reduce the effects of chance and confounding variables, providing a robust framework for making informed conclusions.
What are the Limitations of Hypothesis Testing?
Hypothesis testing relies exclusively on data and doesn’t provide a comprehensive understanding of the subject being studied. Additionally, the accuracy of the results depends on the quality of the available data and the statistical methods used. Inaccurate data or inappropriate hypothesis formulation may lead to incorrect conclusions or failed tests. Hypothesis testing can also lead to errors, such as analysts either accepting or rejecting a null hypothesis when they shouldn’t have. These errors may result in false conclusions or missed opportunities to identify significant patterns or relationships in the data.
The Bottom Line
Hypothesis testing refers to a statistical process that helps researchers and/or analysts determine the reliability of a study. By using a well-formulated hypothesis and set of statistical tests, individuals or businesses can make inferences about the population that they are studying and draw conclusions based on the data presented. There are different types of hypothesis testing, each with their own set of rules and procedures. However, all hypothesis testing methods have the same four step process, which includes stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result. Hypothesis testing plays a vital part of the scientific process, helping to test assumptions and make better data-based decisions.
Sage. " Introduction to Hypothesis Testing. " Page 4.
Elder Research. " Who Invented the Null Hypothesis? "
Formplus. " Hypothesis Testing: Definition, Uses, Limitations and Examples. "
:max_bytes(150000):strip_icc():format(webp)/z-test.asp-final-81378e9e20704163ba30aad511c16e5d.jpg "hypothesis keywords")
- Terms of Service
- Editorial Policy
- Privacy Policy
- Your Privacy Choices
- Features for Creative Writers
- Features for Work
- Features for Higher Education
- Features for Teachers
- Features for Non-Native Speakers
- Learn Blog Grammar Guide Community Events FAQ
- Grammar Guide
How to Write an Abstract (With Examples)

Sarah Oakley

Table of Contents
What is an abstract in a paper, how long should an abstract be, 5 steps for writing an abstract, examples of an abstract, how prowritingaid can help you write an abstract.
If you are writing a scientific research paper or a book proposal, you need to know how to write an abstract, which summarizes the contents of the paper or book.
When researchers are looking for peer-reviewed papers to use in their studies, the first place they will check is the abstract to see if it applies to their work. Therefore, your abstract is one of the most important parts of your entire paper.
In this article, we’ll explain what an abstract is, what it should include, and how to write one.
An abstract is a concise summary of the details within a report. Some abstracts give more details than others, but the main things you’ll be talking about are why you conducted the research, what you did, and what the results show.
When a reader is deciding whether to read your paper completely, they will first look at the abstract. You need to be concise in your abstract and give the reader the most important information so they can determine if they want to read the whole paper.
Remember that an abstract is the last thing you’ll want to write for the research paper because it directly references parts of the report. If you haven’t written the report, you won’t know what to include in your abstract.
If you are writing a paper for a journal or an assignment, the publication or academic institution might have specific formatting rules for how long your abstract should be. However, if they don’t, most abstracts are between 150 and 300 words long.
A short word count means your writing has to be precise and without filler words or phrases. Once you’ve written a first draft, you can always use an editing tool, such as ProWritingAid, to identify areas where you can reduce words and increase readability.
If your abstract is over the word limit, and you’ve edited it but still can’t figure out how to reduce it further, your abstract might include some things that aren’t needed. Here’s a list of three elements you can remove from your abstract:
Discussion : You don’t need to go into detail about the findings of your research because your reader will find your discussion within the paper.
Definition of terms : Your readers are interested the field you are writing about, so they are likely to understand the terms you are using. If not, they can always look them up. Your readers do not expect you to give a definition of terms in your abstract.
References and citations : You can mention there have been studies that support or have inspired your research, but you do not need to give details as the reader will find them in your bibliography.

Good writing = better grades
ProWritingAid will help you improve the style, strength, and clarity of all your assignments.
If you’ve never written an abstract before, and you’re wondering how to write an abstract, we’ve got some steps for you to follow. It’s best to start with planning your abstract, so we’ve outlined the details you need to include in your plan before you write.
Remember to consider your audience when you’re planning and writing your abstract. They are likely to skim read your abstract, so you want to be sure your abstract delivers all the information they’re expecting to see at key points.
1. What Should an Abstract Include?
Abstracts have a lot of information to cover in a short number of words, so it’s important to know what to include. There are three elements that need to be present in your abstract:
Your context is the background for where your research sits within your field of study. You should briefly mention any previous scientific papers or experiments that have led to your hypothesis and how research develops in those studies.
Your hypothesis is your prediction of what your study will show. As you are writing your abstract after you have conducted your research, you should still include your hypothesis in your abstract because it shows the motivation for your paper.
Throughout your abstract, you also need to include keywords and phrases that will help researchers to find your article in the databases they’re searching. Make sure the keywords are specific to your field of study and the subject you’re reporting on, otherwise your article might not reach the relevant audience.
2. Can You Use First Person in an Abstract?
You might think that first person is too informal for a research paper, but it’s not. Historically, writers of academic reports avoided writing in first person to uphold the formality standards of the time. However, first person is more accepted in research papers in modern times.
If you’re still unsure whether to write in first person for your abstract, refer to any style guide rules imposed by the journal you’re writing for or your teachers if you are writing an assignment.
3. Abstract Structure
Some scientific journals have strict rules on how to structure an abstract, so it’s best to check those first. If you don’t have any style rules to follow, try using the IMRaD structure, which stands for Introduction, Methodology, Results, and Discussion.

Following the IMRaD structure, start with an introduction. The amount of background information you should include depends on your specific research area. Adding a broad overview gives you less room to include other details. Remember to include your hypothesis in this section.
The next part of your abstract should cover your methodology. Try to include the following details if they apply to your study:
What type of research was conducted?
How were the test subjects sampled?
What were the sample sizes?
What was done to each group?
How long was the experiment?
How was data recorded and interpreted?
Following the methodology, include a sentence or two about the results, which is where your reader will determine if your research supports or contradicts their own investigations.
The results are also where most people will want to find out what your outcomes were, even if they are just mildly interested in your research area. You should be specific about all the details but as concise as possible.
The last few sentences are your conclusion. It needs to explain how your findings affect the context and whether your hypothesis was correct. Include the primary take-home message, additional findings of importance, and perspective. Also explain whether there is scope for further research into the subject of your report.
Your conclusion should be honest and give the reader the ultimate message that your research shows. Readers trust the conclusion, so make sure you’re not fabricating the results of your research. Some readers won’t read your entire paper, but this section will tell them if it’s worth them referencing it in their own study.
4. How to Start an Abstract
The first line of your abstract should give your reader the context of your report by providing background information. You can use this sentence to imply the motivation for your research.
You don’t need to use a hook phrase or device in your first sentence to grab the reader’s attention. Your reader will look to establish relevance quickly, so readability and clarity are more important than trying to persuade the reader to read on.
5. How to Format an Abstract
Most abstracts use the same formatting rules, which help the reader identify the abstract so they know where to look for it.
Here’s a list of formatting guidelines for writing an abstract:
Stick to one paragraph
Use block formatting with no indentation at the beginning
Put your abstract straight after the title and acknowledgements pages
Use present or past tense, not future tense
There are two primary types of abstract you could write for your paper—descriptive and informative.
An informative abstract is the most common, and they follow the structure mentioned previously. They are longer than descriptive abstracts because they cover more details.
Descriptive abstracts differ from informative abstracts, as they don’t include as much discussion or detail. The word count for a descriptive abstract is between 50 and 150 words.
Here is an example of an informative abstract:
A growing trend exists for authors to employ a more informal writing style that uses “we” in academic writing to acknowledge one’s stance and engagement. However, few studies have compared the ways in which the first-person pronoun “we” is used in the abstracts and conclusions of empirical papers. To address this lacuna in the literature, this study conducted a systematic corpus analysis of the use of “we” in the abstracts and conclusions of 400 articles collected from eight leading electrical and electronic (EE) engineering journals. The abstracts and conclusions were extracted to form two subcorpora, and an integrated framework was applied to analyze and seek to explain how we-clusters and we-collocations were employed. Results revealed whether authors’ use of first-person pronouns partially depends on a journal policy. The trend of using “we” showed that a yearly increase occurred in the frequency of “we” in EE journal papers, as well as the existence of three “we-use” types in the article conclusions and abstracts: exclusive, inclusive, and ambiguous. Other possible “we-use” alternatives such as “I” and other personal pronouns were used very rarely—if at all—in either section. These findings also suggest that the present tense was used more in article abstracts, but the present perfect tense was the most preferred tense in article conclusions. Both research and pedagogical implications are proffered and critically discussed.
Wang, S., Tseng, W.-T., & Johanson, R. (2021). To We or Not to We: Corpus-Based Research on First-Person Pronoun Use in Abstracts and Conclusions. SAGE Open, 11(2).
Here is an example of a descriptive abstract:
From the 1850s to the present, considerable criminological attention has focused on the development of theoretically-significant systems for classifying crime. This article reviews and attempts to evaluate a number of these efforts, and we conclude that further work on this basic task is needed. The latter part of the article explicates a conceptual foundation for a crime pattern classification system, and offers a preliminary taxonomy of crime.
Farr, K. A., & Gibbons, D. C. (1990). Observations on the Development of Crime Categories. International Journal of Offender Therapy and Comparative Criminology, 34(3), 223–237.
If you want to ensure your abstract is grammatically correct and easy to read, you can use ProWritingAid to edit it. The software integrates with Microsoft Word, Google Docs, and most web browsers, so you can make the most of it wherever you’re writing your paper.

Before you edit with ProWritingAid, make sure the suggestions you are seeing are relevant for your document by changing the document type to “Abstract” within the Academic writing style section.
You can use the Readability report to check your abstract for places to improve the clarity of your writing. Some suggestions might show you where to remove words, which is great if you’re over your word count.
We hope the five steps and examples we’ve provided help you write a great abstract for your research paper.
Get started with ProWritingAid
Drop us a line or let's stay in touch via :
Tips for keywords
Get related keywords and automatically group them by popular topics, user intent, keyword pattern, and more. Click a keyword to check the Google SERP or hover a keyword to check the stats.
Do you have a large list of keywords you have to pick from? Import your keyword list to quickly find search volume and competition and automatically grouping them by user intent, popular topics, patterns, and more.
See what is trending related to your company, product, or campaign. Enter any topic, name, industry, or keyword and find out keywords that have emerged on Google News recently with the given word. Click a keyword to check Google News article or hover a keyword to check Google News snippet.
Get the most popular keywords segmented by language, geographical targets, and specific search terms.
Get a list of keywords relevant to your website by entering domain or URL. Useful to understand a competitor’s keyword strategy as well.
Need more keyword ideas? Start exploring LSI (Latent Semantic Indexing) keywords and visualize related keywords for your business. Keyword brainstorming starts here!
Tips for filters
Popular topics.
After getting your initial keyword suggestions, use the topic filter to only show keyword suggestions that are related to a specified topic. You can type any topic or choose one our AI has discovered among the keyword suggestions.
User Intent
User intent is what the searcher is searching for when they type in a specific keyword. Filter the keyword suggestions that has the intents you care about, whether it is the "know", "buy", "do", and local" intent, or all of them.
Keywords Patterns
Pattern is a short cut for your most prominent long tail keywords. To get started, after getting your keyword suggestions, select a pattern. The most common patterns in the suggested results are how, when, best, and cheap.
Include / Exclude
Include or exclude keywords where whole words match. To get started, after getting your keyword suggestions, use the include and exclude pattern filters.
Search Volume
Search Volume indicates how many people have searched with this phrase in the chosen location. The value is an average monthly search volume of the last 12 months of each keyword suggestion. If you see N/A in the search volume or Ads competition columns, it means that no data was available from Google for that keyword.
Keyword Score
Keyword Score (Efficiency column) indicates which keywords are best to include in your SEO content. It is calculated based on search popularity and relative competition to maximize your ranking potential.
Title Score
The title score shows you which keywords make the best titles. It is calculated based on search popularity and relative competition to maximize your ranking potential.
Relevance Score
The relevance column shows a score from 0 to 100 of how semantically related each keyword is to your original search query. You can also change the relevance criteria by clicking the settings gear icon. When you set a new topic the relevance score is based on, the relevance score column in your keyword list will then reflect how close each keyword in the list is to that topic.
SEO Competition
The relative amount of web sites already targeting and competing for each keyword on search engine result pages with the maximum value of 100. This score (Difficulty column) is computed by looking at Google search engine result pages, and it is an estimate based off of algorithms and AI.
Paid Competition
The relative amount of Google Ads competition for each keyword with the maximum value of 100. It comes directly from Google Ads own data.
Cost Per Click
Average bids for the ad to be displayed at the top of the first page. It's based on Google Ads statistics for advertisers, and the value may differ depending on the location.
The number of words in a keyword.
Brainstorm & LSI Words
LSI Keywords are simply related words of a specific topic. The more you include, the more you are relevant to your topic. The more relevant your content, the better you'll rank on search engines in terms of relevance. Boost the topic relevance of content with Context Words, Theme Words, Trending Words, Broad Terms, Narrow Terms, Related Terms, Evocations, Synonyms Associations, Drived Terms, and usages.
News Articles
Read related news articles and discover their connections and relationships. Gain insights on why LSI words are related to your query.
Happy keyword research
IMAGES
VIDEO
COMMENTS
Alternative Hypothesis. The statement that there is some difference in the population (s), denoted as H a or H 1. When writing hypotheses there are three things that we need to know: (1) the parameter that we are testing (2) the direction of the test (non-directional, right-tailed or left-tailed), and (3) the value of the hypothesized parameter.
Developing a hypothesis (with example) Step 1. Ask a question. Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project. Example: Research question.
clearly stated hypothesis or hypotheses • methods used (including brief descriptions of the study design, sample, and sample size) • ... More information on how to write and format an abstract and keywords can be found in the . Publication Manual of the American Psychological Association (7th ed.) Sections 2.9 to 2.10 and in the .
The actual test begins by considering two hypotheses.They are called the null hypothesis and the alternative hypothesis.These hypotheses contain opposing viewpoints. \(H_0\): The null hypothesis: It is a statement of no difference between the variables—they are not related. This can often be considered the status quo and as a result if you cannot accept the null it requires some action.
Table of contents. Step 1: State your null and alternate hypothesis. Step 2: Collect data. Step 3: Perform a statistical test. Step 4: Decide whether to reject or fail to reject your null hypothesis. Step 5: Present your findings. Other interesting articles. Frequently asked questions about hypothesis testing.
Formulating Strong Hypotheses. Before you write your research hypothesis, make sure to do some reading in your area of interest; good resources will include scholarly papers, articles, books, and other academic research. Because your research hypothesis will be a specific, testable prediction about what you expect to happen in a study, you will ...
The alternative hypothesis (H a) is the other answer to your research question. It claims that there's an effect in the population. Often, your alternative hypothesis is the same as your research hypothesis. In other words, it's the claim that you expect or hope will be true. The alternative hypothesis is the complement to the null hypothesis.
A hypothesis (from the Greek, foundation) is a logical construct, interposed between a problem and its solution, which represents a proposed answer to a research question. It gives direction to the investigator's thinking about the problem and, therefore, facilitates a solution. Unlike facts and assumptions (presumed true and, therefore, not ...
Examples. A research hypothesis, in its plural form "hypotheses," is a specific, testable prediction about the anticipated results of a study, established at its outset. It is a key component of the scientific method. Hypotheses connect theory to data and guide the research process towards expanding scientific understanding.
Definition: Hypothesis is an educated guess or proposed explanation for a phenomenon, based on some initial observations or data. It is a tentative statement that can be tested and potentially proven or disproven through further investigation and experimentation. Hypothesis is often used in scientific research to guide the design of experiments ...
hypothesis testing. S.3 Hypothesis Testing. In reviewing hypothesis tests, we start first with the general idea. Then, we keep returning to the basic procedures of hypothesis testing, each time adding a little more detail. The general idea of hypothesis testing involves: Making an initial assumption. Collecting evidence (data).
The actual test begins by considering two hypotheses.They are called the null hypothesis and the alternative hypothesis.These hypotheses contain opposing viewpoints. H 0: The null hypothesis: It is a statement about the population that either is believed to be true or is used to put forth an argument unless it can be shown to be incorrect beyond a reasonable doubt.
A snapshot analysis of citation activity of hypothesis articles may reveal interest of the global scientific community towards their implications across various disciplines and countries. As a prime example, Strachan's hygiene hypothesis, published in 1989,10 is still attracting numerous citations on Scopus, the largest bibliographic database ...
Below these are summarized into six such steps to conducting a test of a hypothesis. Set up the hypotheses and check conditions: Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as H 0, which is a statement of a particular parameter value. This hypothesis is assumed to be true until there is ...
Step 7: Based on steps 5 and 6, draw a conclusion about H0. If the F\calculated F \calculated from the data is larger than the Fα F α, then you are in the rejection region and you can reject the null hypothesis with (1 − α) ( 1 − α) level of confidence. Note that modern statistical software condenses steps 6 and 7 by providing a p p -value.
The process of hypothesis testing involves two hypotheses — a null hypothesis and an alternate hypothesis. The null hypothesis is a statement that assumes there is no relationship between two variables, no association between two groups or no change in the current situation — hence 'null'. It is denoted by H0.
Step 8: Test your Hypothesis. Design an experiment or conduct observations to test your hypothesis. Example: Grow three sets of plants: one set exposed to 2 hours of sunlight daily, another exposed to 4 hours, and a third exposed to 8 hours. Measure and compare their growth after a set period.
Likelihood ratio. In the likelihood ratio test, we reject the null hypothesis if the ratio is above a certain value i.e, reject the null hypothesis if L(X) > 𝜉, else accept it. 𝜉 is called the critical ratio.. So this is how we can draw a decision boundary: we separate the observations for which the likelihood ratio is greater than the critical ratio from the observations for which it ...
2. The scientific hypothesis. In this section, we will describe a functional and descriptive role regarding how scientists use hypotheses. Jeong & Kwon [] investigated and summarized the different uses the concept of 'hypothesis' had in philosophical and scientific texts.They identified five meanings: assumption, tentative explanation, tentative cause, tentative law, and prediction.
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves. ... Preliminary investigation might lead to the hypothesis that a tree-based structure with poor memory locality will be slower in practice than an array-based structure with high locality ...
Hypothesis testing is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used ...
Hypothesis. Keywords. Your context is the background for where your research sits within your field of study. You should briefly mention any previous scientific papers or experiments that have led to your hypothesis and how research develops in those studies. Your hypothesis is your prediction of what your study will show.
Click a keyword to check Google News article or hover a keyword to check Google News snippet. Top. Get the most popular keywords segmented by language, geographical targets, and specific search terms. Site. Get a list of keywords relevant to your website by entering domain or URL. Useful to understand a competitor's keyword strategy as well ...